
做SEO首先就了解搜索引擎工作流程:
(1)爬行抓取
①批量收集:对互联网上存在链接的网页收集一遍,一般需要耗时几周左右;
②增量收集:在原有基础上搜集新增加的网页,更新上次收集完后有改变的页面,删除收集重复和不存在的网页;
③自己提交:自己主动向搜索引擎提交网站,不建议这种方法,因为比较慢。


PS:搜索引擎蜘蛛是搜索引擎的一个自动程序,它的作用就是用来访问互联网上的网页、图片、视频内容。
URL是搜索引擎的痕迹,看搜索引擎是否爬取过你的网站,就看服务器日志是否有该URL。
④搜索引擎蜘蛛爬行策略
搜索引擎蜘蛛主要是通过爬行页面上的链接来收集新的页面,不停的十字交叉爬行下去便形成一张蜘蛛网。
Ⅰ深度优先爬行(A-B-E-A-C-F-H-A-D-G-H)
Ⅱ广度优先爬行(A-B-C-D-E-F-G-H)(最常用的方式,所以很多SEO优化人员会通过网站地图放上网站的所有链接)
PS: 搜索引擎蜘蛛访问层数设置成3的话,H网页将不会被收集到,所以网站结构的扁平化很重要。
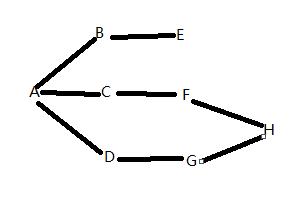
蜘蛛爬行策略
⑤搜索引擎蜘蛛如何避免重复收集
Ⅰ造成重复收集的原因:
蜘蛛没有记录访问过的URL;一个页面由多个域名指向导致。
Ⅱ解决办法:搜索引擎建立了两个表:已访问表、未访问表。
⑥搜索引擎蜘蛛是如何判断网页重不重要
Ⅰ网页目录越小越好用户看着体验好;
Ⅱ原创性内容多,好的,重要性越高;
Ⅲ更新度一个有价值的网站每天都会有更新,用户天天来看,来玩儿;
Ⅳ高质量相关链接导入:一个权重高的,高质量的网页愿意外链接到你的网站,那证明你的网站质量也很好。
(2)预处理
①关键词提取
搜索引擎蜘蛛抓取到的像大量的HTML代码,Javascript,css,div标签等,要去除,搜索引擎完全能识别的还是文字内容,所以关键词提取是把不懂的标签去掉,把文字留下来;
②去除停用词
反复出现的像“得”、“的”、“地”、“啊”、“呀”、“再”等这些无用词称为停用词,去除停用词;
③分词
Ⅰ基于统计的分词方法
分词词典和收录的网络流行词语是搜索引擎的依据,如:我要睡觉了,其他神马都是浮云;
Ⅱ基于字符串匹配的分词方法
例如设置分词词典最大数字是3,那下面这段话的分法:先提取前三个词,我要睡,我要睡词典了没这个词,把睡去掉,留下我要,我要词典里也没这个词,把要去掉,留下我,再提取三个词要睡觉,要睡觉词典里没这个词,把觉去掉,留下要睡,要睡也没这个词,把睡去掉,留下要,再提取三个词睡觉了,睡觉了词典里也没这个词,把了去掉,睡觉词典里有这个词,留下睡觉,接下来的词以此类推。
我要睡觉了,其他神马都是浮云;
我、要、睡觉、了、其他、神马、都是、浮云;

④消除噪声
把网页上各种广告文字、广告图片、版权信息、登录框等等这些信息去除掉;
⑤建立关键词库
提取完关键词后,把页面转换为一个关键词的组合,记录每一个关键词在页面上出现频率,出现次数,格式,位置;
⑥连接关系计算
搜索引擎事先要计算出页面上有那些链接指向那些其他页面,每个页面由哪些导入链接,链接使用了什么锚文本等等;
⑦特殊文件处理
Flash,视频,图片等无法直接读懂。
(3)服务输出
搜索引擎有自己相关的排名机制,主要根据网页的相关度、关键字的密度、网站的权重等,来决定输出的内容排名先后(付费推广的永远排在前面几条)。
相关推荐
2019新版SEO优化方案(从建站到盈利的整个放心)
可能你觉得做网站SEO非常难,而实际上随着搜索引擎的人性化,seo是越来越简单,那么本节课程就是教你如何从0开始到seo大神,最终盈利 。
浅谈百度SEO快排是什么、原理、如何判断及应对
以前我说过不准备写这个快排,一是我自己的网站没有操作过所谓的快排 ,二是我并不能像网上很多写的揭秘百度快排(说实话,你都能揭秘的方法了,还真的很有用吗?真正懂的人都在低调赚money)。我只是站在一个小白角度,让更多小白了解下所谓百度快排是什么,以及同行网站是否使用了所谓快排技术,我们自己又该如何应对它。
做网站SEO怎么赚钱(一篇文章每个月可以赚8000元)
有人说做SEO不赚钱,现在SEO不好做,而实际上现在的SEO非常好做,而且还非常赚钱,小编做SEO有7年时间了,可以说一直在这个行业里面忙碌。今天就给大家分享一下,做SEO怎么赚钱…
seo标签优化方法(细节决定成败)
提个问题,上学的时候,你们是不是也写过“细节决定成败”这种标题的作文?其实做SEO也是这个道理。做SEO前,我们需要理解,流量和排名不是一蹴而就的事,细心、耐心、恒心是做好SEO的…
百度seo排名优化是什么(20个快速上百度首页的方法)
在这个流量泛滥而又稀缺的时代,在做SEO优化排名的过程中,它早已经不是你建立一个企业官网,然后守株待兔的等待访问。 你必须通过线上各种渠道积极主动的营销推广你的品牌、产品。 不可否…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。