
从PC时代到移动互联网时代,搜索满足了人们从海量信息中找到有价值信息的需求,进一步提高了用户的信息消费能力和获取信息效率。
从PC时代到移动互联网时代,搜索满足了人们从海量信息中找到有价值信息的需求,进一步提高了用户的信息消费能力和获取信息效率。笔者曾做过一个比较简单的APP站内搜索功能优化,查阅了许多搜索功能设计资料。
于是乎便有了这篇搜索文章,我将从搜索最主要的三步理解用户搜索意图、召回内容、排序内容来给大家讲讲搜索功能设计的那些事。


大纲如下:
- 搜索是为了解决什么
- 如何设计站内搜索
- 理解用户搜索意图
- 召回内容
- 排序内容
- query分析
- 写在最后
一、搜索是为了解决什么
搜索引擎在PC时代崛起,谷歌、百度通过输入框和网页搜索结果来满足网民的信息消费,帮助网民打破各种信息不对称。谷歌、百度的搜索信息是相对开放的,用户能在上面搜到大部分的内容。
随着移动互联网的普及,许多APP开始构建自己的内容生态,搭建自身的站内搜索。谷歌、百度等搜索引擎时从搜索到内容,这些站内搜索是从内容到搜索,基于自家的内容生态来搭建搜索功能。
对于用户来说,用户搜索内容可分为几种场景:
- 有明确想搜的内容并记得所有关键词
- 有明确想搜的内容但记不清所有关键词
- 无明确想搜的内容
所以对于用户来说,搜索是为了解决用户明确或者不明确的搜索需求,让用户能够搜到想搜的内容。从更深一层来说,搜索提高了用户获取信息、内容的效率。
二、如何设计站内搜索
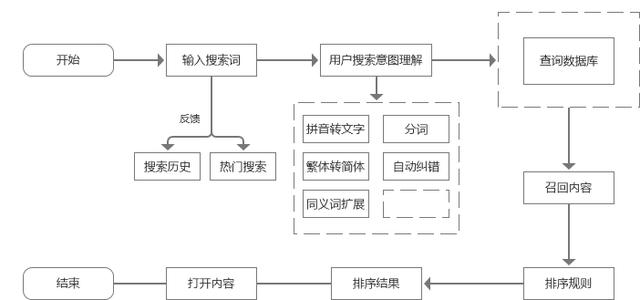
站内搜索对于搜索系统来说,整个流程可以分为三步,分别是:
- 理解用户搜索意图
- 召回内容
- 排序内容
整个流程里,第一步理解用户搜索意图会涉及到query预处理、分词技术等技术,第二步召回相关内容一般用到的是索引倒序的技术,召回有相关性的内容,这里会涉及到倒排索引和匹配度问题。第三步排序内容目前常见的有排序策略、机器学习。
产品经理需要做的主要是画搜索原型图和制定召回相关性策略和排序策略,其他的主要是靠技术或者第三方去实现。
三、理解用户搜索意图
用户搜索是整个搜索系统的上游,只有理解了用户的搜索意图,搜索展现的结果才会是用户想要的。如果对搜索意图理解错了,不论我们的召回率和排序策略多么牛,对用户来说这次的搜索其实是失败的。
那么怎么理解用户的搜索意图呢?用户输入的是关键词,所以我们来分析下怎么理解关键词。(ps:这篇文章只讨论搜索方式为输入文字的方式,不讨论语音输入、图片、视频输入等方式)
3.1 query预处理
3.1.1 拼音转文字
当用户在搜索框中输入拼音时,可以识别出文字。这种搜索场景还是蛮常见的,比如用户想在微信读书中搜索“俞军产品方法论”,那么当用户在搜索框中输入”yujunchnapinfangfalun”时能理解出“俞军产品方法论”,并给出搜索结果。
3.1.2 繁体转简体
对于一些有繁体输入习惯的用户,需要对用户输入的繁体字进行转化,可以识别出其简体。具体方案是通过词表将繁体query转化为简体query,后续系统在将简体query进行召回。
3.1.3 自动纠错
当用户在搜索框中输入“于军”,其实用户想搜的是“俞军”。系统可以对这个query进行判断,判断有没有在索引库命中文档,如果没有,则需要对其进行预处理的自动纠错。
自动纠错可以通过维护纠错表的方式实现。在纠错表里通过映射原词给纠错后的词,从而实现query改写。
目前自动纠错在客户端显示上也有几种不同的形式:
- 强纠错:直接改写query,给用户的提示一般为“已显示XXX的搜索结果”
- 中纠错:直接改写query,给用户的提示一般为“已显示XXX的搜索结果,仍然搜索:X原词XX”
- 弱纠错:不改写query,只是给用户提示“你是不是要搜索:XXX”
3.1.4 同义词转换
同义词转换从字面上理解就是能够对query进行同义词的理解。比如当用户输入“首都机场”,可以理解为“北京机场”,用户输入“国宝”,可以理解为“大熊猫”。
同义词转换技术对于query意图理解非常重要,很多时候用户不能很好地输出自己想搜索的内容,如果没有同义词转换技术进一步处理,那么召回的内容很有可能并不是用户想要的。
同义词转换技术一般是通过获取用户的session日志来分析相关的query。
举个例子,比如一个用户输入”国宝“后,查询出来的结果不是想要的,从而没有点击行为。该用户接着输入“大熊猫”,得到了想要的搜索结果并点击了内容。那么“国宝”和”大熊猫“之间就建立了联系。
当然,”国宝“也有可能和”国家宝藏”、“国家文物”等建立联系,基于统计后,可以计算出“国宝”与别的词的联系权重。在召回相关性内容时,对关键词和同义词进行召回,并赋予不同的权重,权重分值可以放在相关性分数上。
3.2 分词技术
以微信读书为例子,目前微信读书的搜索结果内容为书、公众号文章、公众号。比如用户在微信读书上输入“无限的游戏”,用户的意图是想查找一本名为“有限与无限的游戏”的书,不过记错为“无限的游戏”。
如果词典里没有“无限的游戏”这个词,那么就无法返回对应的内容,用户的搜索就到此结束。
词典的词是有限的,输入的关键词是无限的。为了解决这种情况,目前搜索系统主要是通过分词技术来实现。分词的意思是将关键词切分成多个词。
比如“无限的游戏“可以切分为“无限”“的”“游戏”,采用不同的分词技术出来的分词结果也不同。比如有了“无限”“的”“游戏”后,分词会对应到词典里的词,有对应的索引内容,召回了“有限与无限的游戏”这本书。
中文分词目前有三种分词方法,分别是:
- 基于词典的分词
- 基于语法的分词
- 基于统计的分词
第一种基于词典的分词方法用的比较多,我简单地为大家介绍一下。
基于词典的分词指的就是系统有一个词典库,当query的分词与词典的词对应上了,就能召回词典对应的索引文档。
分词的粒度也是至关重要的,目前有许多这方面的规则和算法。比较经典的有正向最大匹配、逆向最大匹配的规则、MMSEG算法。
经过分词切割后,用户非标准的query就能被切分成标准的分词,并能在词典中匹配到词,从而能索引回相关的内容。
当然产品经理不需要精通这些技术,了解概念和实现的结果即可。产品经理提出来的需求有可能是技术部门不支持的,或者不是该功能的最优方案。所以了解这些最基本的技术原理,有助于我们更好地设计搜索功能和提合理的搜索需求。
四、召回内容
4.1 倒排索引技术
这一节,我们需要先说下搜索很核心的技术——倒排索引技术。
搜索系统有词典和内容索引库(数据库),词典里的词关联匹配内容索引库。当用户输入关键词后,如果词典里有这个词,线上会快速召回内容文档。如果词典里没有这个词,那这次的搜索行为就没有结果。
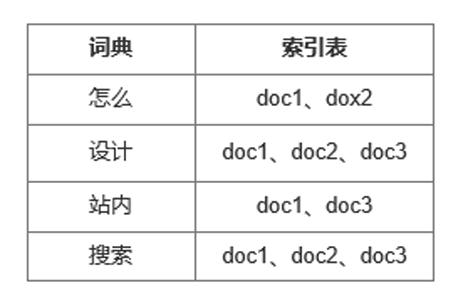
假设内容索引库一共只有3个内容文档,分别是:
- doc1:站内搜索从0到1全流程设计
- doc2:搜索应该怎么设计才是对的
- doc3:产品小白怎么入门站内搜索设计
用户输入关键词“怎么设计站内的搜索”,经过分词后,词典里有这个词,系统会召回对应的索引文档。
索引库如下图所示:
以新闻搜索来说,一条新闻讯息一般会有标题、简介、关键词、来源、正文。
在召回内容的时候,会根据新闻的这几个属性分别构建倒排索引。当然需要召回的字段属性是需要考虑的,并非所有属性都得进行索引召回。
比如可以只对标题和简介这两个属性进行倒排索引召回。召回的时候,我们认为标题跟关键词匹配度高于简介跟关键词的匹配度,可以先以标题为维度倒排索引进行召回,接着再从简介进行召回。
这样的分级索引库有利于提高检索效率,同时能较快将优质和匹配度高的内容检索出来。
五、排序内容
召回相关的内容后,如何排序呢?排序的策略决定了用户最终看到怎样的搜索结果,所以这部分是相当重要的,同时也是比较复杂的。
我这里提供两种排序策略,一种粗排,一种精排(精排、粗排的叫法只是我为了区分两种排序策略而定义的)。产品经理要根据具体的搜索业务和需求来制定搜索排序策略。
5.1 粗排策略
粗排主要是通过维度来将召回的内容进行排序。以某新闻app为例,搜索结果只是新闻(新闻内容包括图文、纯文本、视频)。召回的范围是新闻标题和摘要。
召回的内容匹配度分两个等级:
- 完全匹配
- 模糊匹配(前缀、后缀、分词等)
排序策略:
优先度:新闻标题>摘要,在优先度下按照下方的策略:
I.完全匹配>模糊匹配
II.时效性(以天为单位)
III.阅读量优先
以上的粗排策略只是为了讲解,具体的维度和排序指标不一定是我上面提及的。
5.2 精排策略
精排策略是根据doc分数倒序排序。用户输入query后,召回了doc(内容),这些doc怎么排序呈现给用户呢?答案是根据每个doc的分数倒序呈现给用户。
doc分数=文本相关性的值*重要度的值。
文本相关性的值用dscore表示、重要度的值用Iscore来表示,则doc分数=dscore*Iscore。
5.2.1 文本相关性
文本相关性的数值怎么计算呢?目前业界计算相关性的方法主要有三种,分别是tf-idf文本相关性、基于统计词频的BM25、空间向量模型。
我在这里给大家介绍下非常经典的tf-idf文本相关性方法。这个方法不仅简单,并且能解决80%以上的搜索结果相关性问题。
5.2.1.1 Tf-idf
Tf-idf中的tf全称为Term Frequence,指的是词频,是指该词在某文本的占比。Tf越高,说明该词在文本中越重要。
Idf全称为Inverse Document Frequence,指的是逆文档频率。在说idf前先介绍下df,df是文档频率,是将包含该Term的文档数除以总文档数。比如一个Term在10个文档出现,总共有50个文档,那么df值为10/50(1/5)。
讲完df后,我们再聊回idf,还是上面的例子,那么idf值为log(50/10)。由公式可以看出,idf越高,说明有该Term的文本越少,那么该文本越就能代表该Term。
同时用log来表示,还能处理掉一些高频词对文本相关性的干扰。比如“的”“了”,这种高频词的Tf可能很高,但Idf会很小,接近于0,两数值相乘后也会很小,能很好的排除这些高频词的噪音。
对于较为简单的文本相关性排序,相关性的分值可以用Tf*idf来表示,分值越高,说明文本相关性越高。
5.2.1.2 词距与词序
query被切割分词成多个term后,term之间的距离与顺序跟文本相关性有关。
举个例子,用户搜索“产品方法论”,在索引库里恰好有两个文档为“俞军产品方法论”和“做产品的10个方法”,很明显召回排序时,“俞军产品方法论”应该要比“做产品的10个方法”排在更前。
但可能这两个文档的Tf*idf值是一样的,因为“产品”和“方法”这两个term都有。所以我们需要关注term之间的距离和顺序,在计算相关性分值时考虑进来,从而保证紧密度更高的term在召回的文档中出现距离更近更相关。
5.2.1.3 term位置
不同位置相关性的重要程度会不同,以新闻搜索来说,标题与关键词的相关性是要重要于简介与关键词的相关性的。一般这种情况下,可以赋予一个系数到Tf*idf,最终dscore=a*Tf*idf(a是系数,比如标题可以赋予1,简介赋予0.8)
5.2 重要度
重要度指得是doc(内容)的重要程度(优质程度)。相关性得分差不多的内容里会存在优质内容和劣质内容,一般情况下,我们会将优质内容排在更前面。当然也会有商业、广告或者别的业务的考虑,这种情况下重要度得分就会更加复杂一些。
重要度得分(Tscore)由于跟query没有直接关系,是每一个doc的实时属性,所以这一部分的分数可以离线算好。
还是以新闻搜索为例,假设一条新闻最重要的三个指标是阅读量、评论率、时效性。那么:Tscore=a*f(阅读量)+b*f(评论量)+c*f(时效性)。
f(阅读量)、f(评论量)、f(评论量)这三个都是函数。一般来说,这三个函数可以为对数函数(log函数),因为对数函数是递增函数,但其导数为递减函数,说明随着阅读量增大,f(阅读量)值也会增大,但增大趋势在下降,即增大程度越来越小。
这样有助于冷却一些优质数据,想要获得更高分数会越来越困难,使得马太效应的强度降低一些。
三个对数函数还会存在一个问题,即没有归一化。比如阅读量的值会在0-100000,评论率在0-1之间,时效性以小时来算的话,时效性的值可以在0-8760(以上数值不具备参考意义,单纯是为了讲解)。
三个指标的值不在同一区间,会严重影响最终的重要度得分(Tscore)的真实性。所以需要将三个指标的值归一化,消除量纲,将数据值按比例缩放。
归一化有几种常见的方法,有取分数、min-max标准化、Z-score标准化方法等,通过这些方法将三个指标的取值范围控制在0~1。(具体归一化操作大家可自行搜索,不在此展开)
如何确定a、b、c三个值呢?
一般有两种办法:
- 专家、产品自行决定(拍脑袋或者通过多组数据来得出)
- 通过机器学习来训练,得出a、b、c的值
验证这些值是不是对的,可以通过A/Btest、搜索功能上线后的数据来验证。
六、query分析
搜索功能搭建好之后,如果搜索功能对于整体业务来说很重要,那么我们需要不断地优化搜索功能。优化搜索功能不单单只是优化搜索策略和算法,还可以通过query分析来提升用户搜索体验。
query分析指的是对用户的查询进行分析,用户的搜索轨迹能够很好的帮助我们了解整体用户的搜索意图,也能发现我们目前的搜索满足了用户哪些搜索需求,哪些搜索需求还需要完善。
query分析可以分以下几步来操作:
1、以月份为单位,从query中抽取1000个query样本
2、针对query意图进行分类,每个query样本用两个需求分类来表征该query的搜索需求
3、统计一类需求、二类需求query个数的占比情况和搜索次数占比情况
query个数占比=分类query个数/query总数
query搜索次数占比=分类query搜索次数/总query搜索次数
4、统计几个数据:
query召回率=搜索结果在准确的数量/应该被搜索的结果数量
query准确率=搜索结果在准确的数量/返回的结果数量
query需求满足程度,可以根据搜索结果质量得出query需求满足程度,分为高中低三等级
通过以上四步,我们能获得相应的数据统计,接下来就是需要对数据结果进行分析,通过分析来决策下一步搜索需要怎么优化。
举个例子,比如在query需求满足度中,分析出需求满足度低的query需求是哪些,查看搜索结果,分析是什么原因导致。
可能会是数据缺失、搜索结果相关度低等原因引起,那么我们后面如果需要提高这类query需求的用户搜索体验的话,那么就需要去解决数据缺失、搜索结果相关度低的问题。
- 如果是数据缺失,那么可以通过引入外面的内容、加大该类内容供给
- 如果是搜索结果相关度低,那么可以改善匹配策略,召回更相关的内容
七、写在最后
写到最后才发现写了这么多,其实一个完整的站内搜索不仅仅只是这些,理解用户搜索意图、召回内容、排序内容这三步可以优化的地方实在是太多了。
随着搜索需求越来越高,传统的方法无法满足一些搜索场景和目的。所以我们早已开始从算法工程和机器学习切入,这部分我暂时还未涉及,不过最近有在看算法,看看后面能不能从算法的角度来跟大家讲讲如何提高对用户搜索意图分析、如何提高搜索相关性等。
谈到搜索,在中文搜索里绕不开俞军老师。最后贴一下俞军老师当年求职搜索工作的求职信,体会下这封至今读来依旧带有传奇色彩的求职信。
搜索引擎9238,男,26岁,上海籍,同济大学化学系五年制,览群书,多游历。97年7月起在一个国营单位筹备进口生产项目。99年4月起在一个代理公司销售进口化工原料兼报关跟单。2000年1月起在一个垂直网络公司做分析仪器资料采编。2000年7月起去一个网络公司应聘搜索引擎产品经理,却被派去做数据库策划,9月起任数据中心经理。长期想踏入搜索引擎业,无奈欲投无门,心下甚急,故有此文。如有公司想做最好的中文搜索,诚意乞一参与机会。
本人热爱搜索成痴,只要是做搜索,不计较地域(无论天南海北,刀山火海),不计较职位(无论高低贵贱一线二线,与搜索相关即可),不计较薪水(可维持个人当地衣食住行即是底线),不计较工作强度(反正已习惯了每日14小时工作制)。
相关推荐
2019新版网站运营策划方案(3天IP破万的推广方式)
现在是2019了,不要在拿着老一套的方法来运营推广自己的产品,市场在变化,咱们的网站运营策划也的根据时代的变化而变化,今天小编给大家分享一套目前来讲最靠谱的网站运营方案。 SEO推…
90%的成功企业都在用这样的商业模式!
你可能觉得诺基亚不卖手机了就一定会倒闭,而实际上诺基亚依然在盈利,而且可能比以前过的还要好,你可能觉得08年金融危机来的时候,遭殃的肯定是大品牌的传统行业,而实际上都不是。 但我们…
2019微信公众号吸粉的方法(学点皮毛一天轻松加5000粉丝)
毫无疑问微信公众号是最容易拿到微信端的渠道之一,即使目前微信公众号的效果不如以前,但是依然可以为你创造很大的利润,今天小编给大家分享一套2019年非常靠谱的公众号吸粉方法。 上图是…
产品运营最好的三大法宝(学会一招用一生)
我们在运营产品的时候,不能按照常规的思路来运营,而实际上每一次成功营销的背后绝对有这三大逻辑。 意大利佛罗伦萨有一家玩具商店,上面有一个非常醒目的广告标语“7岁以上的顾客不可以单独…
2019年小县城冷门暴利生意(投资不大但非常赚钱)
是不是觉得现在外面打工越来越难,钱越来越难赚了,其实并非如此,而是时代变了,我们需要随着时代的变化而变化。那么今天小编给大家分享的就是2019年小县城的冷梦暴利生意,可以说投资非常…
2019最实用的推广引流方法(学会了每天固定IP不低于一万)
很多人在说,有流量就一定有生意,但是没有流量一定没有生意,所以很多人都在说,目前是流量为王的年代,今天咱们就来说说,目前最有效的引流推广的方式。 上图是小编的一个小网站,一天下来流…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。