
今天给大家实操的案例是泰坦尼克号生存率的分析,这个案例已经有很多人写过,算是个比较经典的案例,通过船上乘客的信息分析和建模,预测哪些乘客得以生还,对数据分析新手来说很有学习价值,本篇就带大家用这个数据集进行一次完整的数据分析
使用工具:Excel(对,就是这么简单粗暴),数据集获取方式见文末
一、明确目的
1912年泰坦尼克号撞上冰山沉没,船上2224名乘客和机组人员中有1502人遇难,幸存下来的人是出于运气还是存在一定的规律?这是我们比较关心的,所以就要提出问题:
那些人士生还的可能性大?
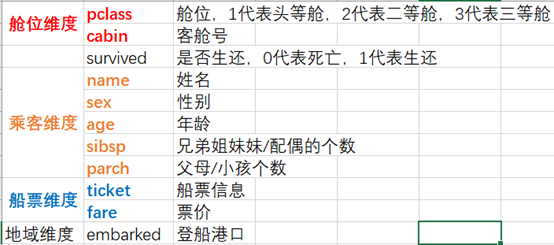
其次了解数据,数据集总共有以下的字段,其中name、sex、cabin、embarked、ticket是字符串类型,pclass和survived虽然是数值型,但其含义是标签,我们分别从舱位、乘客、船票和地域的维度出发来分析。

二、数据处理
通过查看,发现Age、fare、embarked、cabin字段都是有缺失的,下面我们一个一个来看。
1、age缺失值处理
筛选age一列为空的有263条数据,缺失率为20%,可以全部填充为年龄的均值或众数,也可以进一步地分析,发现年龄缺失的数据里三等舱的最多,占总缺失值的79%,而三等舱里的未生还的男性占比最多,因此也可以用三等舱年龄的平均值来填充。
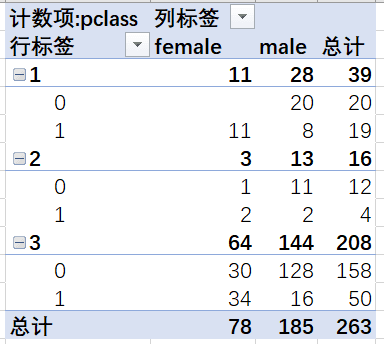
这里为了保持数据的真实性,就不做填充处理了
2、fare缺失值处理
筛选发现fare(票价)只缺失了一个值,我们把它找出来,发现可以用同类型的均值填充掉。

因此我们筛选三等舱、年龄大于60岁的,登船港口为S的男性的均值票价7来填充这个缺失值。

3、embarked缺失值处理
embarked登船港口字段也有2个缺失值,筛选出来看下。

进一步观察到,这两个旅客都是单独出行,没有家人(从sibsp和parch列均为0得知),延续对fare缺失值处理的思路,寻找同类型的进行填充。对第一个旅客,筛选出头等舱的年龄在35~40岁的女性中,港口最多的值填充进去,结果是S。
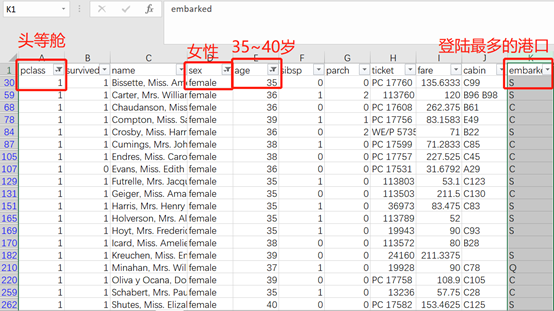
同样的方法,对第二个旅客,筛选头等舱年龄在60~65岁的女性中,登陆港口最多的值,结果也为S。

4、cabin缺失值处理
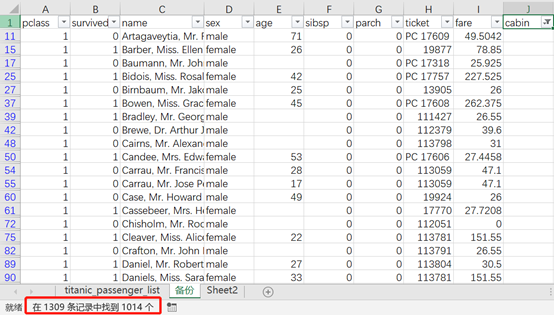
对于cabin(客舱)字段缺失值达到了77%,缺失太多了,就不做填充处理了,直接保留或删除,这里先保留着吧。
三、数据分析
1、舱位维度
pclass对舱位和生还情况分析,插入数据透视表

生还的人里,头等舱的占比达到了40%。
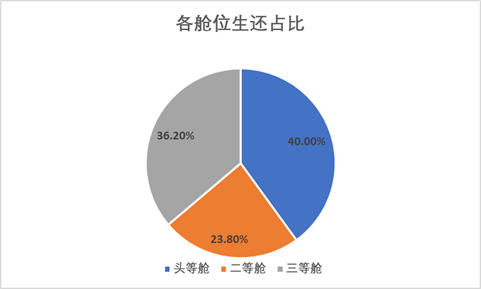
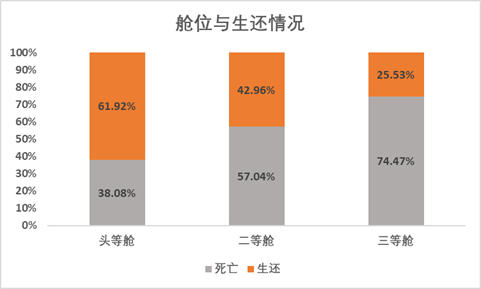
对每个舱位的生存死亡情况做百分比堆积柱形图,可以看到,头等舱生还的人数占比最多,达到61.92%,三等舱的生还人数占比最少,仅25.33%,所以还是那句老话,钱虽然不是万能的,但没钱@#%&^…
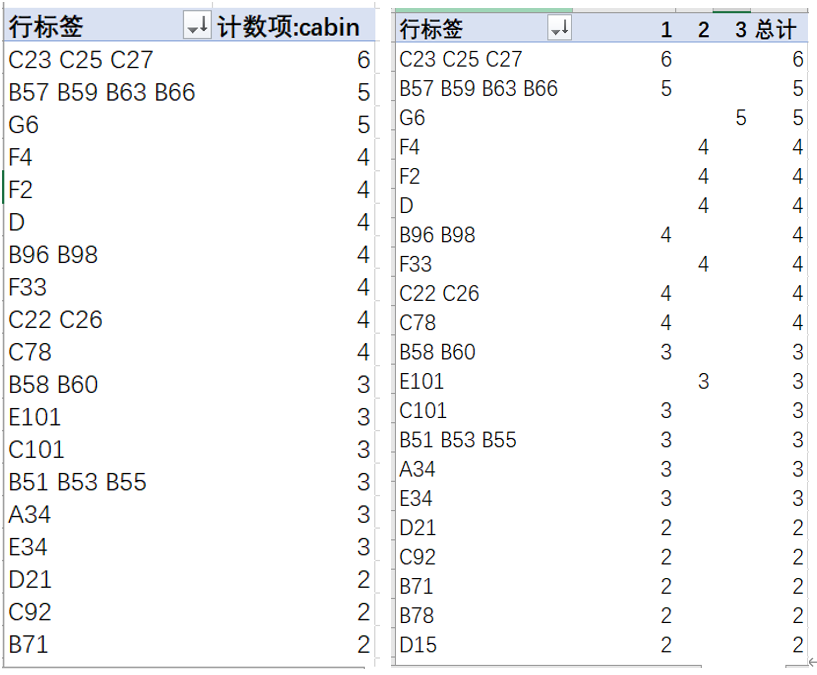
carbin对carbin(客舱号)做透视,可以看到有295个唯一值,基本上是一个客舱只住一个人。

但是也发现了有1个客舱对应2个人以上的情况,进一步地把舱位拉进去对比一下,发现三等舱的数值很少,说明carbin缺失值大部分是三等舱缺失的,意思是三等舱的人没有客舱?大通铺?这个有待进一步查证。
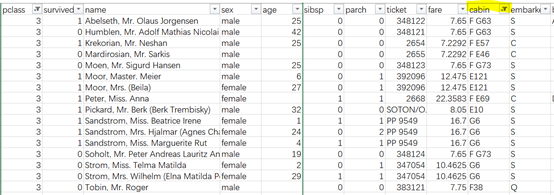
另外发现三等舱有客舱的都是E/F/G开头的客舱号,而头等舱A/B/C就较多,猜测客舱号是随着舱位的降低按字母升序排列的。
2、乘客维度
namename姓名列没有什么有价值的信息,不过可以进一步思考的是,姓名里其实是对应了头衔的,比如Mr是已婚男士,Mrs是已婚女士等,但是这里就先删除了。
sex对性别和生还情况进行分析

生还的人中女性占比67.8%,远高于男性的32.2%。
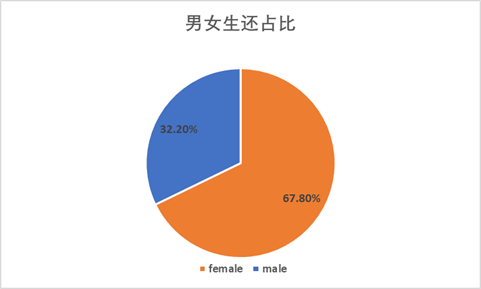
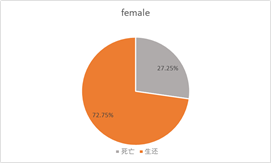
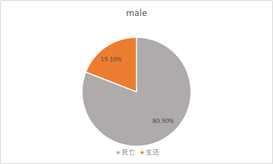
女性生还人数占女性总数的72.75%,远远大于男性生还人数占男性总数的19.10%。
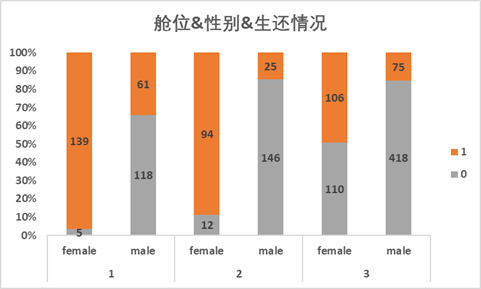
性别&舱位可以顺便看一下舱位和性别的关系,因为男性人口基数大,所以不管是哪个舱位,男性人数都是多于女性的,同理,各个舱位都是女性获救的人数最多。
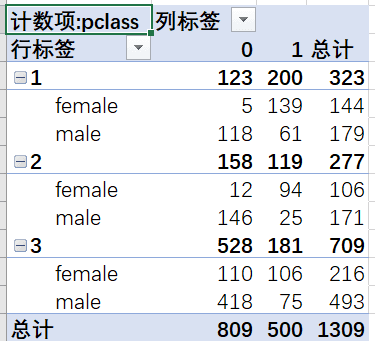
但是呢,头等舱女性的生还比例为97%,远高于其他两个舱位,且三等舱女性的生还比例只有49%。
age对年龄和生还情况进行分析,这里因为年龄有缺失,仅对有数值的进行分析。
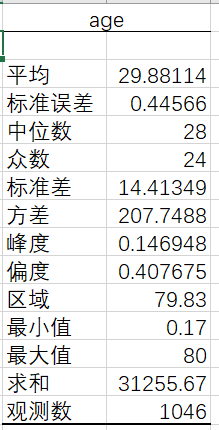
首先对年龄做一个简单的描述统计,用【数据分析】里的【描述统计】功能,可以看到年龄最大值为80岁,最小值为0.17岁,平均值为29.88岁,年龄中位数为28岁,众数为24岁。
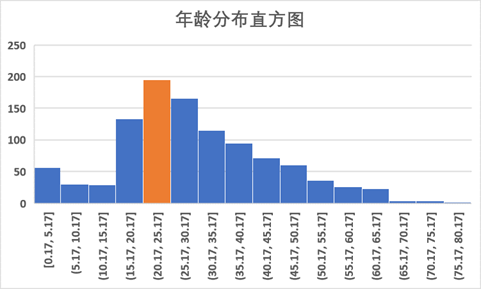
进一步地,可以观察一下年龄的分布情况,做直方图,5岁为一组,可以看到,乘客的年龄主要集中在15-30岁,其中20-25岁的年轻人最多。
了解了年龄大致的分布后,就要来看特定人群的生还情况了,我们将年龄分为:
- 少年(0~15岁)
- 青年(15~40岁)
- 中年(41~65岁)
- 老年(66岁以上)
先做一个分组的表,用vlookup的模糊匹配实现分组
在age旁新建一列age分组的辅助列,输入公式
=VLOOKUP(E2,Sheet2!$B$18:$C$21,2,1)Sheet2!18:21这个区域就是上图预先设置好的分组区域。

再对age分组和survived进行透视
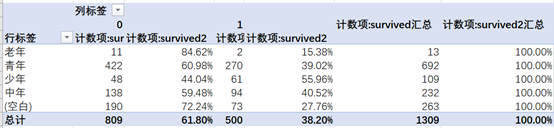
可以看到生还的人中青年、少年的占比最多,老年占比最少。
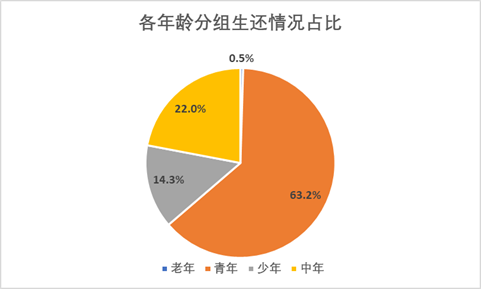
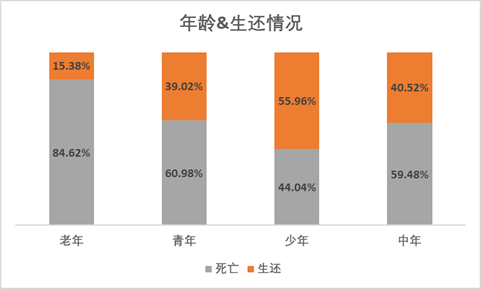
对各年龄段分组的死亡、生存情况做百分比堆积柱形图,得到结果,少年获救的人数比例最高。
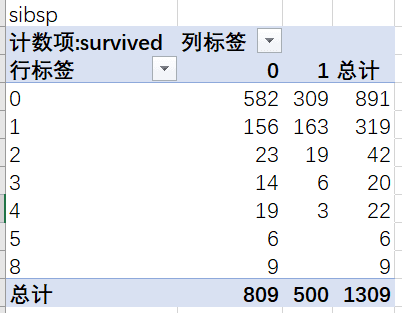
sibsp对sibsp字段(兄弟姐妹妹/配偶的个数)分析,透视后可以看到标签为0,也就是说没有亲戚的人是船上乘客的大多数。
同样因为基数大的缘故,生存下来的人中,亲戚数为0的占比最多达到了61.8%。
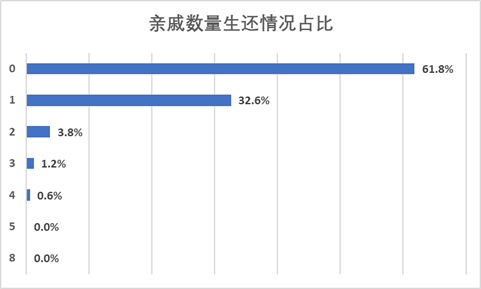
对各标签做百分比堆积柱形图,这才是比较有意义的结果,可以看到,有1个亲戚数的人群获救的比例最高。
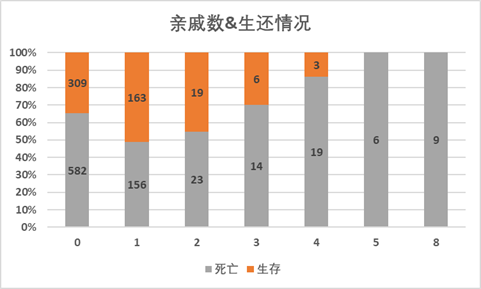
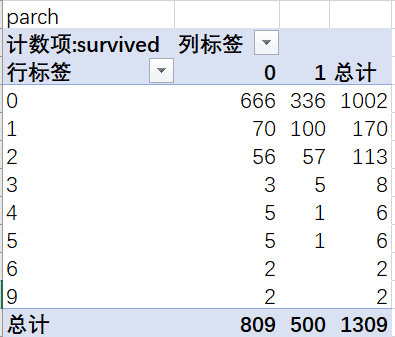
parch对parch字段分析(父母/小孩个数),同样可以看到,没有父母/小孩的人数是船上总人数的76%,同样,这部分人群获救的数量也最多。
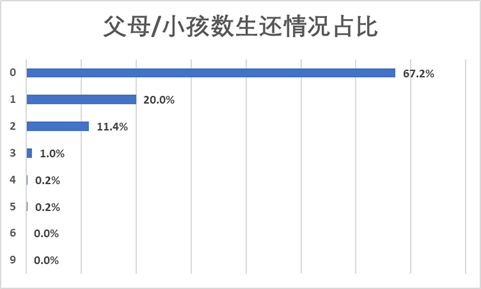
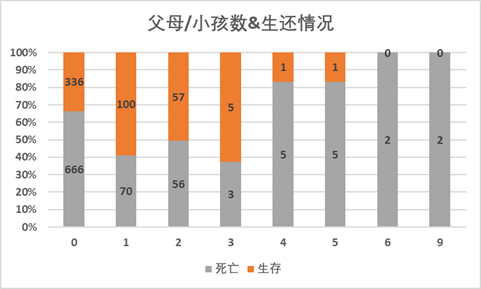
做百分比堆积柱形图,可以看到有3个父母/小孩的人群获救的比例最大,达到了62.5%。
3、船票维度
fare对Fare(票价)字段分析,首先比较关注的是票价和舱位是否存在相关性,正常的逻辑是舱位越高,票价越高,这里算出pclass和fare的相关系数是-0.56,还是比较相关。
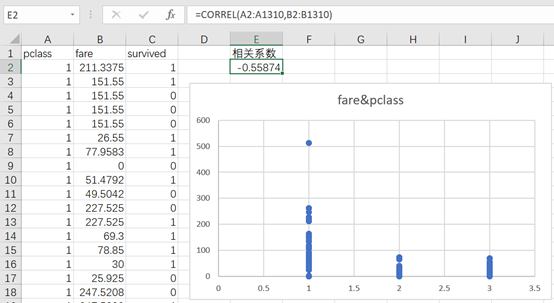
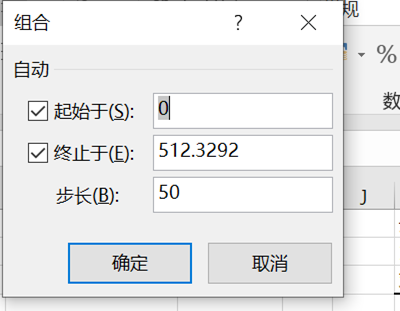
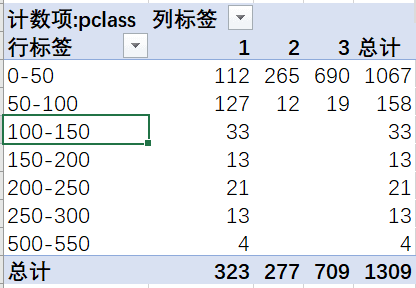
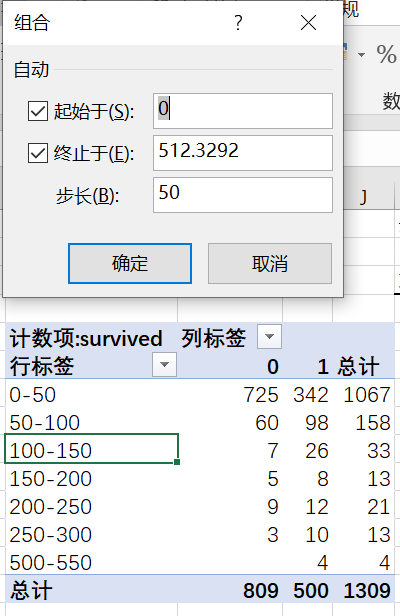
还记得上面我们用vlookup的模糊匹配分组,还可以直接用数据透视表分组。透视以后组合,选择50步长一组,可以再对票价和舱位透视看看,看到100以上的高票价全都是头等舱,二等舱和三等舱的票价大部分为0~50。
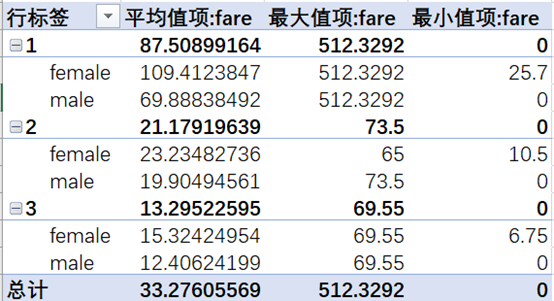
性别&票价女性的票价均价要高于男性
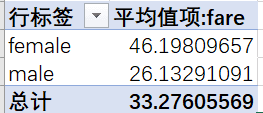
性别&舱位&票价头等舱的均价远高于其他两个舱,每个舱女性的均价都要高于男性,其中票价的最大值512出自头等舱的女性。另外一个比较有意思的现象是,票价为0的居然都是男性。
都写到这儿了,可以再引申出一个问题,票价到底和什么有关?性别?登陆港口?舱位?客舱?有兴趣的小伙伴可以自己再深入探讨一下,这里我们就不探索下去了。
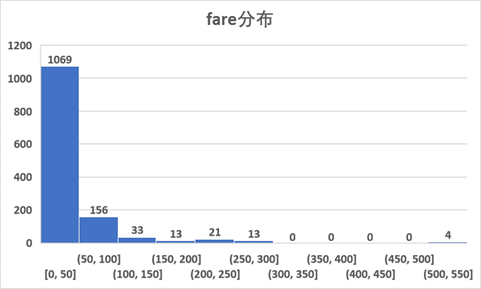
接下来,50一组看一下fare的分布情况,可以看到票价为0~50的占了船上乘客的82%。
同时存活数量最多的还是0~50票价的人群,因为它的基数本身就很大。
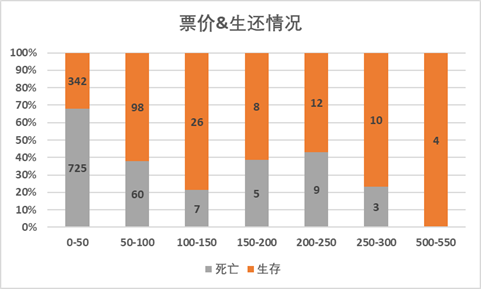
从各票价分组的角度来看,做百分比堆积柱形图,可以看到,500-550票价的人群存活比例为100%,而0-50票价的存活比例只有32%。
ticketticket字段是船票信息/代号,没有特别大的分析意义,这里也就直接删除了。
4、地域维度
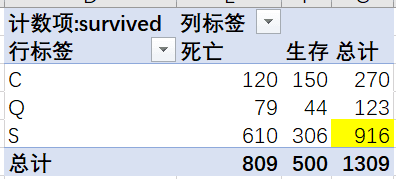
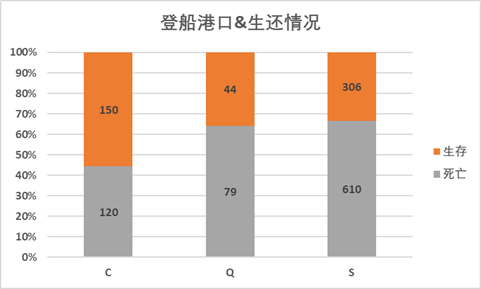
embarked对embarked(登船港口)字段分析,透视后发现S港口登船的人数最多,从堆积柱形图中可以看到,C扣登船的生成比例最高。
四、生还率同什么有关
生还率同什么相关?这个是我们最关心的,这个问题其实就是survived字段同其他字段的相关系数。
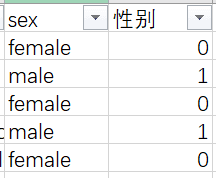
sex列是字符型数据,要映射成数值,我们添加一列命名为性别的辅助列,male为1,female为0.
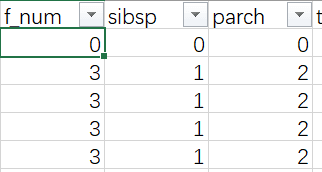
再添加一列f_num字段,是sibsp和parch的和,意思是家庭成员数。
embarked字段分解为3个辅助列,港口-S,港口-C,港口-Q,同时输入公式:
=IF(N2="S",1,0)如果embarked这个字段是S,那么港口-S列为1,港口-C、港口-Q为0,以此类推。
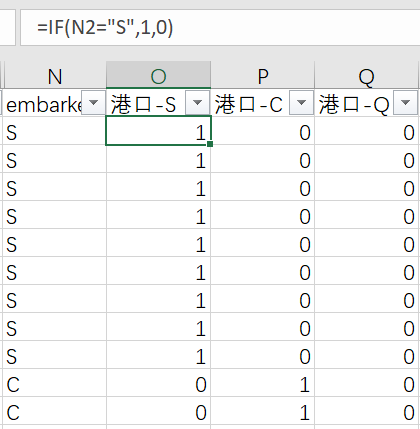
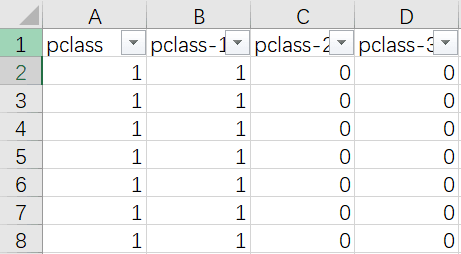
同理对舱位pclass也做同样的处理
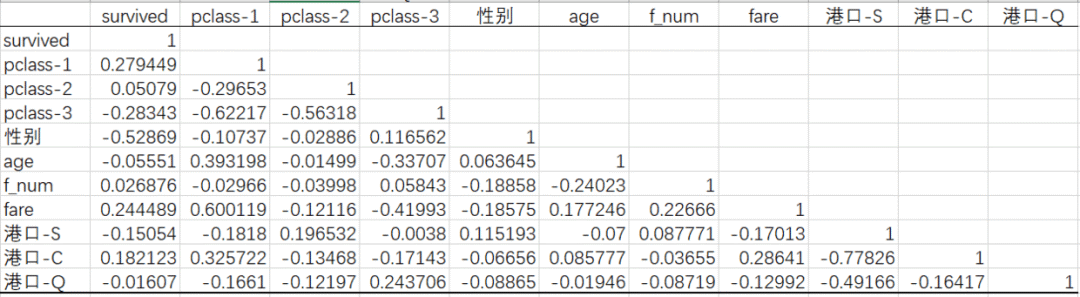
用【数据分析】里的【相关系数】功能,可以看到每个字段的相关系数
降序排列一下,就可以看出生还率同什么相关了
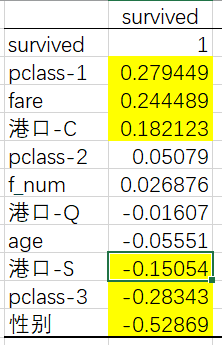
所以回到我们最初的问题:
哪些人生还的可能性大?
总结一下:
- 虽然三等舱的人数最多(54%),但头等舱生还的比例最高(62%)
- 虽然男性的人数(64%)多于女性,但女性的生还率(72%)远高于男性(19%)
- 头等舱女性的生还比例(97%)远高于三等舱女性的生还比例(49%)
- 15-40岁的青年人数最多(53%),生还率最高的是0~15岁的少年(56%)
- 亲戚的个数为0的人数最多(68%),为1的生还率最高(51%)
- 父母/孩子个数为0的人数最多(76%),为3的生还率最高(63%)
- 票价在0-50范围内的人数最多(82%),但500~550范围内票价的人生还率为100%
- S港口登船的人数最多(70%),但是C港口生还率最高(56%)
相关推荐
数据分析:详解2种常见的分析方法
无论是产品功能还是运营策略,都需要通过数据来提供参考与指导。本文通过业务场景和案例呈现,详细拆解2种最常见的数据分析方法——对比分析法和控制变量分析法,让我们的数据分析少走弯路。
2019创业项目排行榜(农村创业项目数据分析)
越来越多的人关心着创业方向的发展,在未来发展中,创业项目要有稳定的市场才能随时代发展被淘汰。并且具有一定特色才能在市场中立足,才能成为长期发展的事业。创业项目有哪些?整合了2019…
未来什么专业吃香(大数据分析这个行业最靠谱)
2020年国家公务员报名正在进行时,未来很多想让孩子考公务员的学生家长要留心了。专业,可以说是考生在报考国家公务员考试时最大的限制条件之一了。专业不对口,其他都白搭。据观察,很多考…
如何制作报表进行数据分析(文员必学的基本知识)
在工作中,经常会制作并填写各种报表(如下图),然后对数据进行统计汇总。 例如:要对公司员工的个人信息统计,填写:哪个部门、什么学历、职称等等。通常我们都是选中该单元格输入内容,或者…
你真的懂数据分析吗?4个方面深入了解数据分析
“大数据”、“数据驱动”这些词汇,对沉浮在互联网的厂工们来说并不陌生,隔着屏幕,一边在源源不断地生产数据,一边在紧锣密鼓地收集解读数据。这些数据是奇妙的,它可以让人更加直观、清晰地认识世界,也可以指导人更加理智地做出决策。
实体店+小程序,引流拓客数据分析是关键(运营方法五)
微信小程序推出也有几年的时间了,很多朋友也对其有了一定的了解,小程序软件应用有着很多功能玩法,这也成为企业商家用来实现引流拓展营销的原因。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。