
1.1 介绍
福哥今天要给大家讲讲Python的正则表达式的使用技巧,正则表达式(Regular expressions)就是通过一系列的特殊格式的匹配符号去描述一个字符串的工具。
使用正则表达式可以快速检测字符串的格式,也可以从字符串里面查找出符合特定规则的字符串片断,还可以将字符串按照特定的规则替换或者重组成新的字符串。
2. 正则表达式
2.1 表达式
2.1.1 re.compile
使用re.compile方法可以定义一个pattern,用来使用其他方法调用这个pattern。
url = "https://tongfu.net/home/35.html"
pattern = re.compile(r"tongfu.net", re.I)
print(re.findall(pattern, url))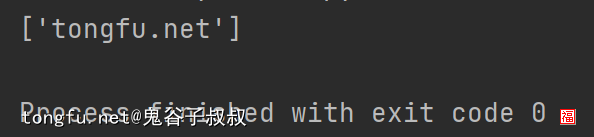

2.1.2 re.template
re.template方法和re.compile方法类似,可以达到相同的目的。
url = "https://tongfu.net/home/35.html"
pattern = re.template(r"tongfu.net", re.I)
print(re.findall(pattern, url))2.2 匹配
2.2.1 re.match
re.match可以实现使用pattern去匹配字符串,结果是一个对象,可以有很多功能可以使用。
re.match是从字符串开头进行匹配的,pattern如果不包含字符串开头部分的话,匹配一定会失败!
url = "https://tongfu.net/home/35.html"
match = re.match(r"https://([^/]+)/home/(d+).html", url)
print(match.group())
print(match.groups())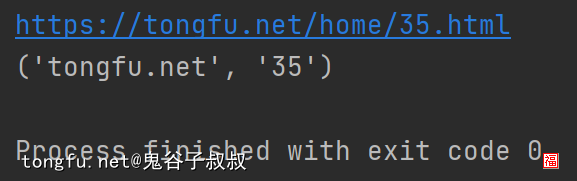
2.2.2 re.search
re.search和re.match类型,区别在于re.search不是从字符串开头匹配的。
如果我们的pattern本身就是从字符串开头匹配的话建议使用re.match,因为效率它更快!
url = "https://tongfu.net/home/35.html"
match = re.search(r"home/(d+).html", url)
print(match.group())
print(match.groups())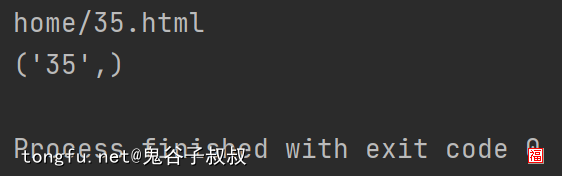
2.2.3 re.findall
re.findall可以直接返回一个tuple数组,而且可以实现多组匹配。
urls = "https://tongfu.net/home/35.html,"
"https://tongfu.net/home/8.html"
matches = re.findall(r"https://([^/]+)/home/(d+).html", urls)
print(matches)
2.3 替换
2.3.1 re.sub
使用re.sub可以将pattern匹配的字符串片断替换为我们想要的内容,这里面还可以将pattern中的匹配组应用到替换内容里面。
urls = "https://tongfu.net/home/35.html,"
"https://tongfu.net/home/8.html"
matches = re.sub(r"/home/(d+).html", r"/homepage/1.htm", urls)
print(matches)
2.3.2 re.subn
re.subn和re.sub在字符串替换功能上面没有区别,re.subn比re.sub多了一个替换次数的统计,这个会在返回值里面体现出来。
urls = "https://tongfu.net/home/35.html,"
"https://tongfu.net/home/8.html"
matches = re.subn(r"/home/(d+).html", r"/homepage/1.htm", urls)
print(matches)
2.4 修饰符
修饰符就是参数flags,用来对pattern进行一个补充。
| 修饰符 | 描述 |
|---|---|
| re.I | 忽略大小写敏感,就是不管大小写问题,字母对就算匹配了。 |
| re.L | 本地化识别匹配。 |
| re.M | 多行匹配,默认正则表达式会在遇到换行符后结束匹配,设置这个之后就会一直匹配到末尾。 |
| re.S | 使字符“.”匹配换行符,默认字符“.”是不包括换行符的。 |
| re.U | 使用Unicode解析字符串,它会影响“w”,“W”,“b”,“B”的作用。 |
| re.X | 这个福哥还没有研究过,官方说法就是可以让编写pattern更加简单。 |
3. 总结
今天福哥带着童鞋们学习了Python的正则表达式库re的使用技巧,正则表达式在各种语言的编程时候都是非常重要的库,使用正则表达式可以让我们处理字符串变得更加简单、更加优雅~~
相关推荐
下载python安装教程(如何下载安装python)
1-1 安装Python 3.7.0 解释器 首先需要说一下,Windows系统主要讲解Win 7环境下Python3.7.0的安装操作。推荐Win XP和win 10的Pytho…
python编程规范要求(新手入门必知python代码编写规范)
注释是编写程序中的一种必不可少的、公认的风格规范,对于他人使得他人更易于读懂理解,对于编写者也易于维护和修改。 这种默认规则从编程语言一开始到现在一直被认可,每种语言都有其注释写法…
python获取网页数据违法吗(解密python技术合法性评估)
近几年来,因为开发者使用爬虫技术锒铛入狱的案例越来越多。 2015年,某公司授意五名程序员,利用网络爬虫获取一公司服务器的公交车行驶信息、到站信息等数据。这五名程序员需承担连带责任…
python自动化测试用例编写(教你编写自动化测试用例)
前言 编写正常的测试用例,一般都是通过excel进行编写的,当我们进行编写自动化测试用例的时,也是通过功能用例进行编写的,那么有没有方法直接通过python读取我们的excel然后…
python命令行参数有什么用(详解python命令行参数作用)
借鉴 C 语言的历史,学习如何用 Python 编写有用的 CLI 程序。 本文的目标很简单:帮助新的 Python 开发者了解一些关于 命令行接口 (CLI)的历史和术语,并探讨…
python自动化框架搭建过程(分享python接口自动化框架有哪些)
用python+selenium实现UI自动化测试,要有一些HTML和xpth的基础,当然python基础一定是必须要会的。笔者建议花点时间了解下相关基础知识,不至于后面发懵。 一…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。