


1、第一个示例,我们要来进行简单的爬虫来爬别人的网页
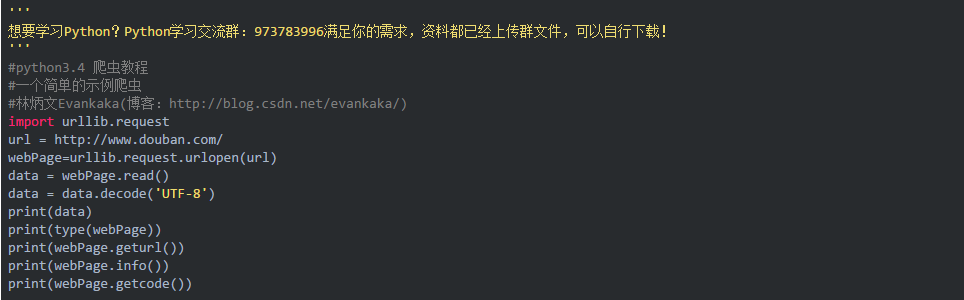
这是爬回来的网页输出:
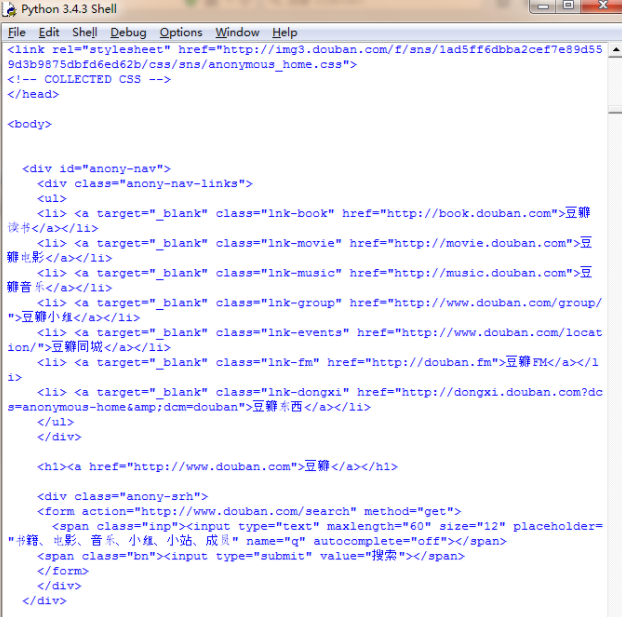
这中间到底发生了什么事呢?让我们打开Fiddler来看看吧:
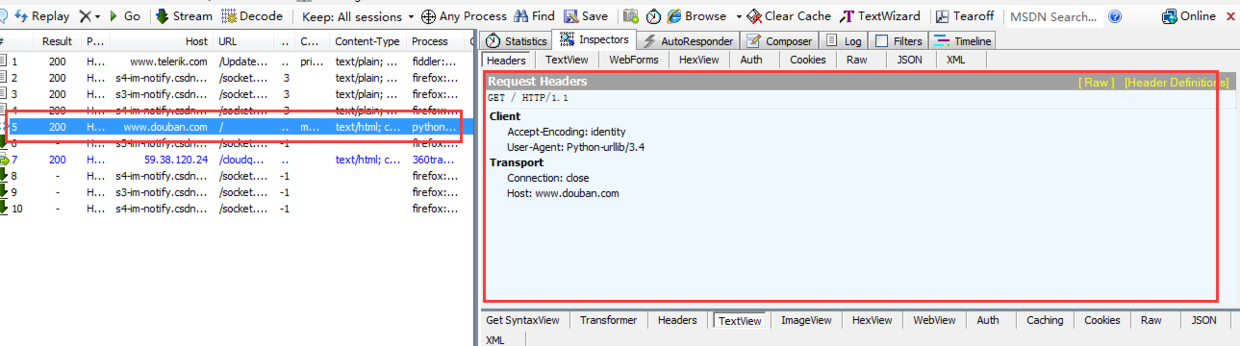
左边标红的就表示我们本次访问成功,为http 200
右边上方这是python生成 的请求报头,不清楚看下面:
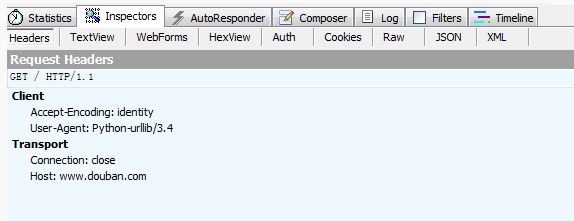
很简单的一个报头,然后再来看看响应回来的html
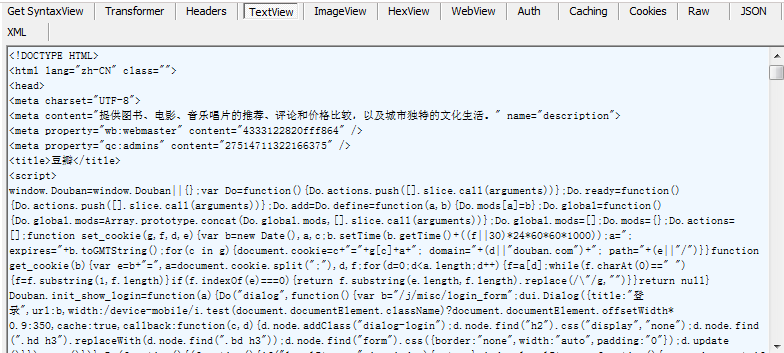
这里响应回来的就是我们上面在python的idle中打印出来的网页了!
2、伪装成浏览器来爬网页
有些网页,比如登录的。如果你不是从浏览器发起的起求,这就不会给你响应,这时我们就需要自己来写报头。然后再发给网页的服务器,这时它就以为你就是一个正常的浏览器。从而就可以爬了!
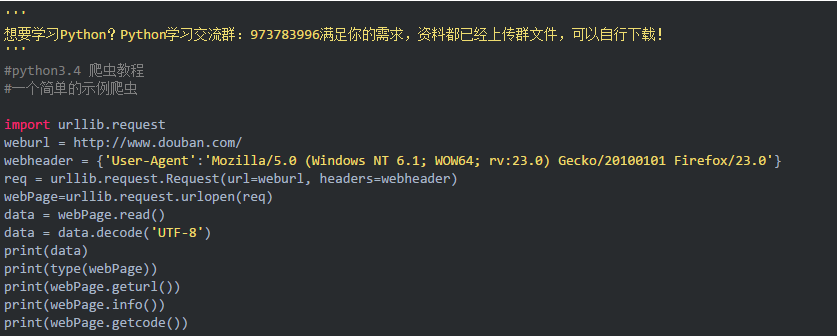
3、爬取网站上的图片
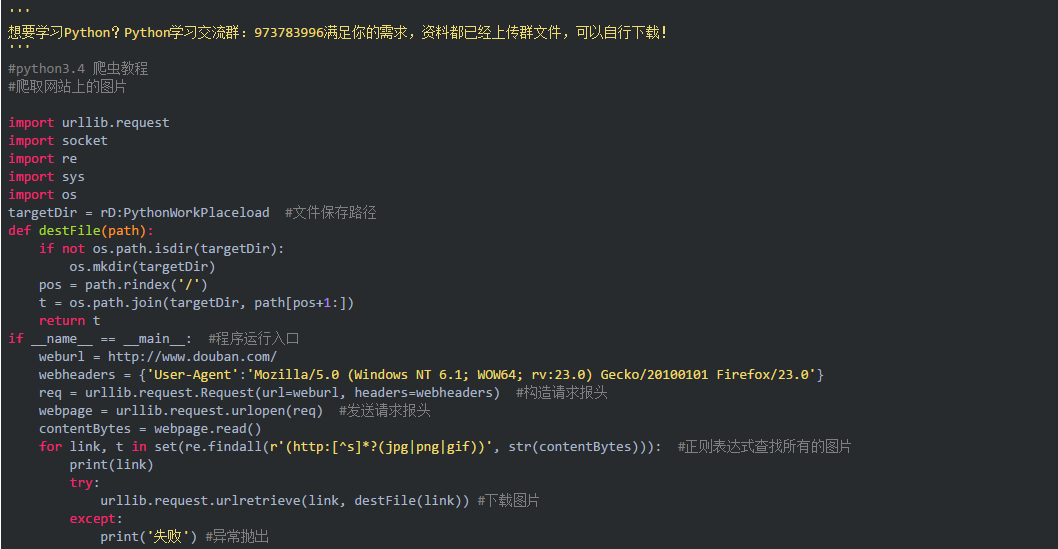
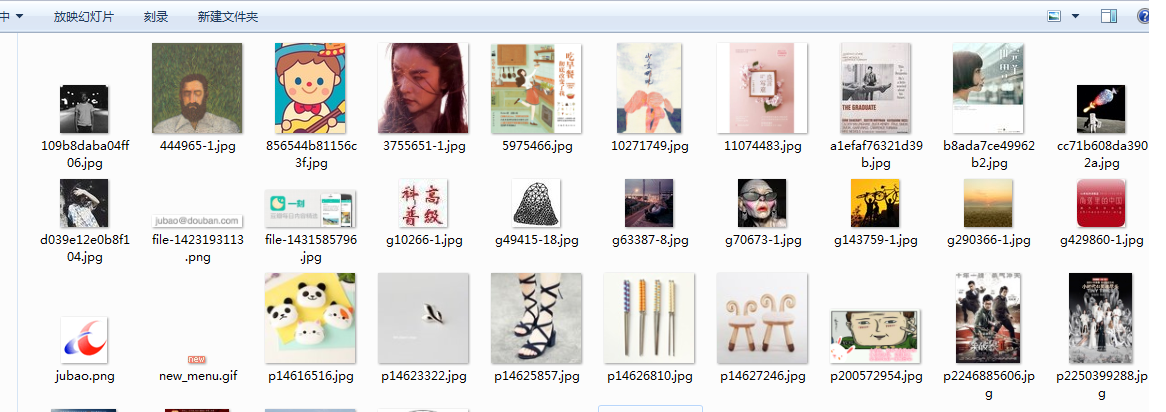
Python3.x 自动登录
python3.4代码编写:
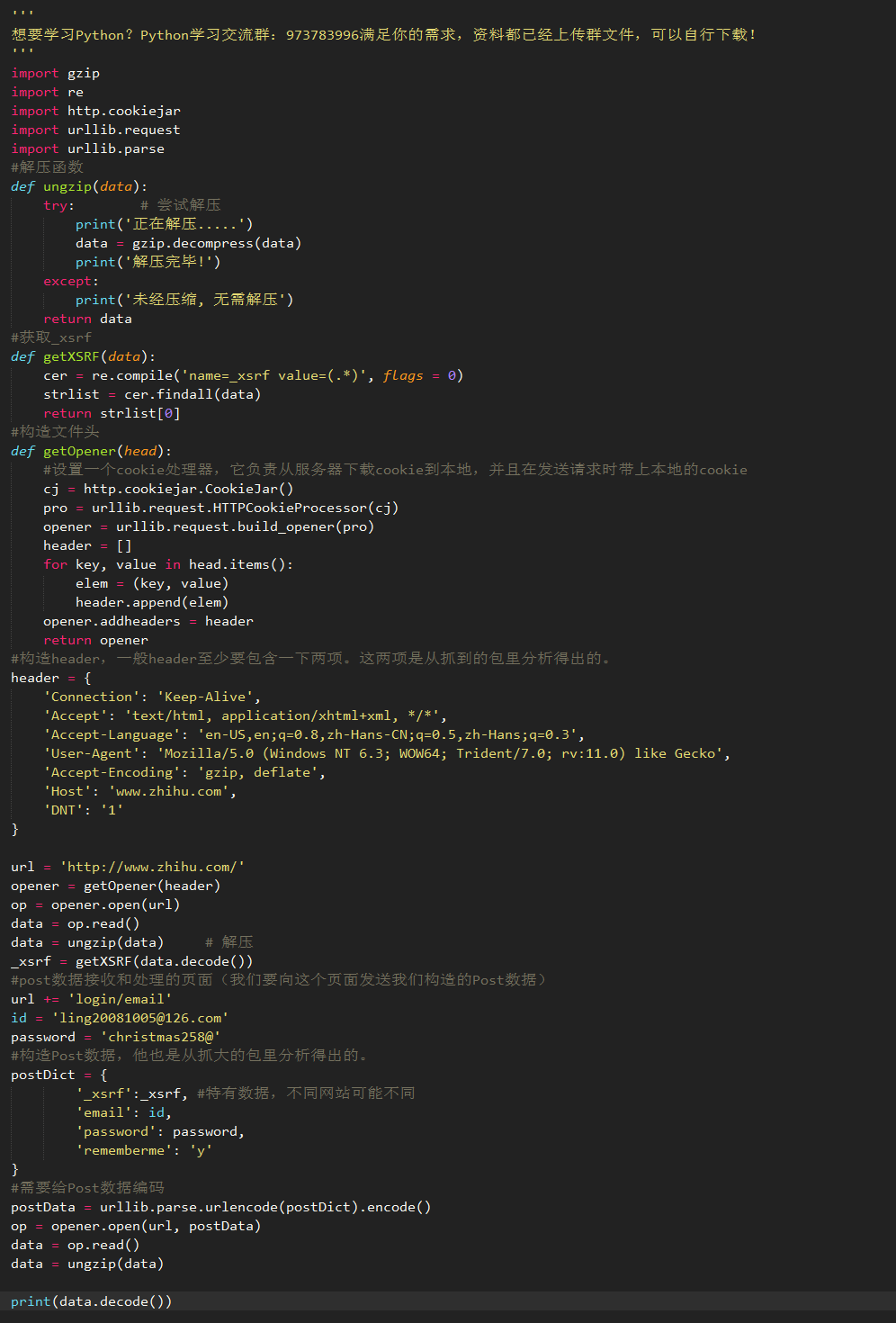
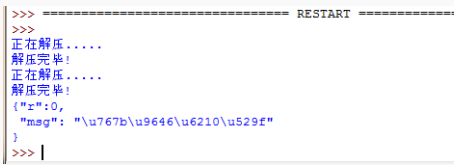
来看看结果:
这时运行返回的
相关推荐
下载python安装教程(如何下载安装python)
1-1 安装Python 3.7.0 解释器 首先需要说一下,Windows系统主要讲解Win 7环境下Python3.7.0的安装操作。推荐Win XP和win 10的Pytho…
python编程规范要求(新手入门必知python代码编写规范)
注释是编写程序中的一种必不可少的、公认的风格规范,对于他人使得他人更易于读懂理解,对于编写者也易于维护和修改。 这种默认规则从编程语言一开始到现在一直被认可,每种语言都有其注释写法…
python获取网页数据违法吗(解密python技术合法性评估)
近几年来,因为开发者使用爬虫技术锒铛入狱的案例越来越多。 2015年,某公司授意五名程序员,利用网络爬虫获取一公司服务器的公交车行驶信息、到站信息等数据。这五名程序员需承担连带责任…
python自动化测试用例编写(教你编写自动化测试用例)
前言 编写正常的测试用例,一般都是通过excel进行编写的,当我们进行编写自动化测试用例的时,也是通过功能用例进行编写的,那么有没有方法直接通过python读取我们的excel然后…
python命令行参数有什么用(详解python命令行参数作用)
借鉴 C 语言的历史,学习如何用 Python 编写有用的 CLI 程序。 本文的目标很简单:帮助新的 Python 开发者了解一些关于 命令行接口 (CLI)的历史和术语,并探讨…
python自动化框架搭建过程(分享python接口自动化框架有哪些)
用python+selenium实现UI自动化测试,要有一些HTML和xpth的基础,当然python基础一定是必须要会的。笔者建议花点时间了解下相关基础知识,不至于后面发懵。 一…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。