
数据分析
简介
每个数据分析都包含一些标准的活动
- 预处理 – 考虑离群值以及缺失值,并对数据进行平滑处理以便确定可能的模型。
- 汇总 – 计算基本的统计信息以描述数据的总体位置、规模及形状。
- 可视化 – 绘制数据以便确定模式和趋势。
- 建模 – 更全面地描述数据趋势,以便预测新数据值。
数据分析通过这些活动,以实现两个基本目标:
- 使用简单模型来描述数据中的模式,以便实现正确预测。
- 了解变量之间的关系,以便构建模型。
此部分说明如何在 MATLAB® 环境中执行基本数据分析。
数据的预处理
Try This Example
此示例显示如何预处理分析用的数据。
概述
通过将数据加载到合适的 MATLAB® 容器变量并区分“正确”数据和“错误”数据,开始数据分析。这是初级步骤,可确保在后续的分析过程中得出有意义的结论。
加载数据
首先加载 count.dat 中的数据:
load count.dat
这个 24×3 数组 count 包含三个十字路口(列)在一天中的每小时流量统计(行)。
缺失数据
MATLAB NaN(非数字)值通常用于表示缺失数据。通过 NaN 值,缺失数据的变量可以维护其结构体 – 在本示例中,即在所有三个十字路口中的索引都是一致的 24×1 向量。
使用 isnan 函数检查第三个十字路口的数据是否存在 NaN 值:
c3 = count(:,3); % Data at intersection 3c3NaNCount = sum(isnan(c3))
c3NaNCount = 0
isnan 返回一个大小与 c3 相同的逻辑向量,并且通过相应条目指明数据中 24 个元素内的每个元素是存在 (1) 还是缺少 (0) NaN值。在本示例中,逻辑值总和为 0,因此数据中没有 NaN 值。
离群值部分的数据中引入了 NaN 值。
离群值
离群值是与其余数据中的模式明显不同的数据值。离群值可能由计算错误所致,也可能表示数据的重要特点。根据对数据及数据源的了解,确定离群值并决定其处理方法。
确定离群值的一种常用方法是查找比均值
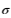

大一定数目的标准差
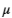
的值。下面的代码绘制当
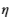
= 1、2 时第三个交点的数据直方图以及
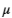
和
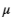
+
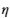
的直线:
bin_counts = hist(c3); % Histogram bin countsN = max(bin_counts); % Maximum bin countmu3 = mean(c3); % Data meansigma3 = std(c3); % Data standard deviationhist(c3) % Plot histogramhold onplot([mu3 mu3],[0 N],'r','LineWidth',2) % MeanX = repmat(mu3+(1:2)*sigma3,2,1);
Y = repmat([0;N],1,2);
plot(X,Y,'g','LineWidth',2) % Standard deviationslegend('Data','Mean','Stds')
hold off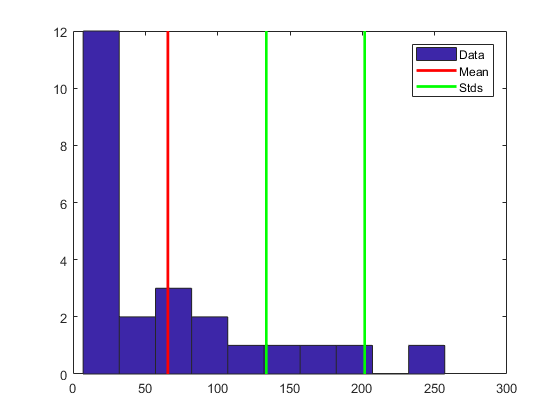
此绘图表明某些数据比均值大两个标准差以上。如果将这些数据标识为错误(而非特点),请将其替换为 NaN 值,如下所示:
outliers = (c3 - mu3) > 2*sigma3; c3m = c3; % Copy c3 to c3mc3m(outliers) = NaN; % Add NaN values
平滑和筛选
第三个十字路口的数据时序图(已在离群值中删除该离群值)生成以下绘图:
plot(c3m,'o-') hold on
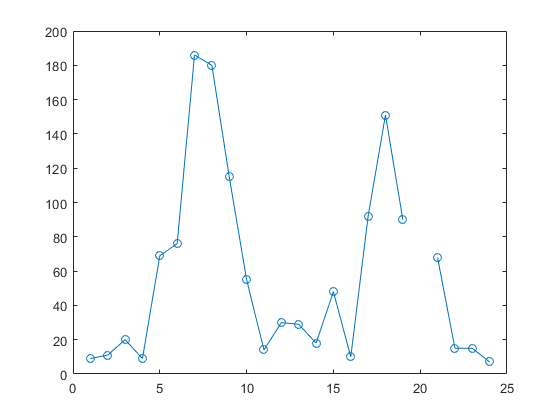
在绘图中,第 20 个小时的 NaN 值出现间隔。这种对 NaN 值的处理方式是 MATLAB 绘图函数所特有的。
噪音数据围绕预期值显示随机变化。您可能希望在构建模型之前对数据进行平滑处理,以便显示其主要特点。平滑处理应当以下面两个基本假定为基础:
– 预测变量(时间)和响应(流量)之间的关系平稳。
– 由于已减少噪音,因此平滑算法生成比预期值更好的估计值。
使用 MATLAB convn 函数对数据应用简单移动平均平滑法:
span = 3; % Size of the averaging windowwindow = ones(span,1)/span;
smoothed_c3m = convn(c3m,window,'same');
h = plot(smoothed_c3m,'ro-');
legend('Data','Smoothed Data')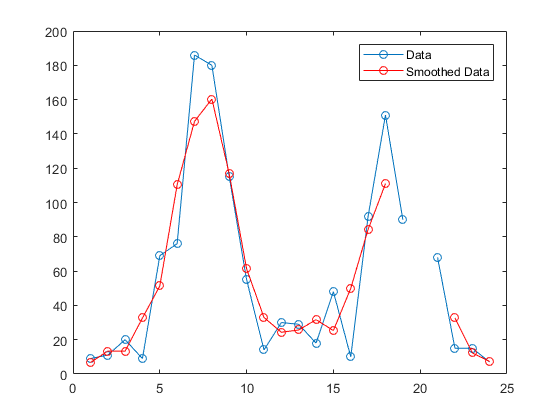
使用变量 span 控制平滑范围。当平滑窗口在数据中包含 NaN 值时,平均值计算返回 NaN 值,从而增大平滑数据中的间隔大小。
此外,还可以对平滑数据使用 filter 函数:
smoothed2_c3m = filter(window,1,c3m); delete(h) plot(smoothed2_c3m,'ro-','DisplayName','Smoothed Data');
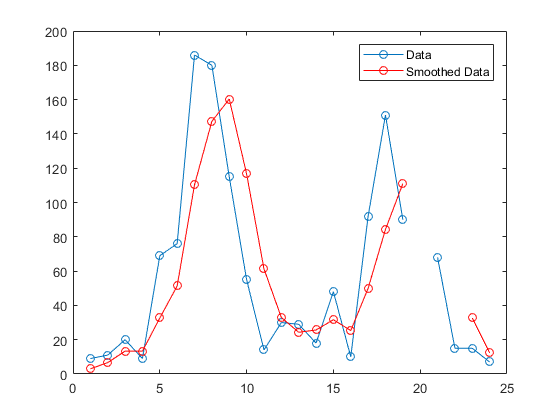
平滑数据在以上绘图的基础上发生了偏移。带有 'same' 参数的 convn 返回卷积的中间部分,其长度与数据相同。filter 返回卷积的开头,其长度与数据相同。否则算法相同。
平滑处理可估计预测变量的每个值的响应值分布的中心。它使许多拟合算法的基本假定无效,即预测器的每个值的错误彼此独立。相应地,您可以使用平滑数据确定模型,但应避免使用平滑数据拟合模型。
汇总数据
Try This Example
此示例显示如何汇总数据。
概述
许多 MATLAB® 函数都可以用于汇总数据样本的总体位置、规模和形状。
使用 MATLAB® 的一大优点是:函数处理整个数据数组,而不是仅处理单一标量值。这些函数称为向量化函数。通过向量化可以进行有效的问题公式化(使用基于数组的数据)和有效计算(使用向量化统计函数)。
位置度量
通过定义“典型”值来汇总数据示例的位置。使用函数 mean、median 和 mode 计算常见位置度量或“集中趋势”:
load count.datx1 = mean(count)
x1 = 32.0000 46.5417 65.5833
x2 = median(count)
x2 = 23.5000 36.0000 39.0000
x3 = mode(count)
x3 = 11 9 9
与所有统计函数一样,上述 MATLAB® 函数汇总多个观测(行)中的数据,并保留变量(列)。这些函数在一次调用中计算三个十字路口中的每个十字路口的数据位置。
规模度量
度量数据示例的规模或“离散度”有多种方法。MATLAB® 函数 max、min、std 和 var 计算某些常见度量:
dx1 = max(count)-min(count)
dx1 = 107 136 250
dx2 = std(count)
dx2 = 25.3703 41.4057 68.0281
dx3 = var(count)
dx3 = 1.0e+03 * 0.6437 1.7144 4.6278
与所有统计函数一样,上述 MATLAB® 函数汇总多个观测(行)中的数据,并保留变量(列)。这些函数在一次调用中计算三个十字路口中的每个十字路口的数据规模。
分布形状
汇总分布的形状比汇总分布的位置或规模更难。MATLAB® hist 函数绘制直方图,可视化显示汇总数据:
figure
hist(count)
legend('Intersection 1',...
'Intersection 2',...
'Intersection 3')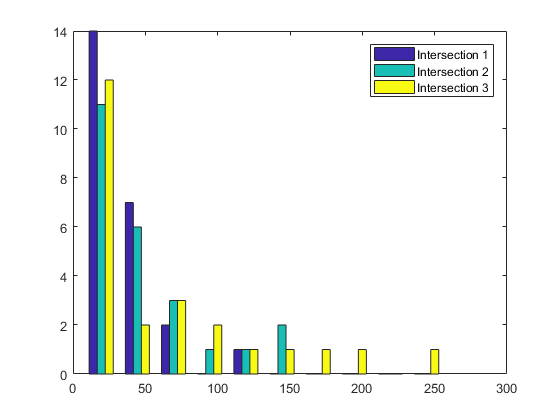
参数模型提供分布形状的汇总分析。指数分布和数据均值指定的参数 mu 非常适用于流量数据:
c1 = count(:,1); % Data at intersection 1[bin_counts,bin_locations] = hist(c1);
bin_width = bin_locations(2) - bin_locations(1);
hist_area = (bin_width)*(sum(bin_counts));
figure
hist(c1)
hold onmu1 = mean(c1);
exp_pdf = @(t)(1/mu1)*exp(-t/mu1); % Integrates
% to 1t = 0:150;
y = exp_pdf(t);
plot(t,(hist_area)*y,'r','LineWidth',2)
legend('Distribution','Exponential Fit')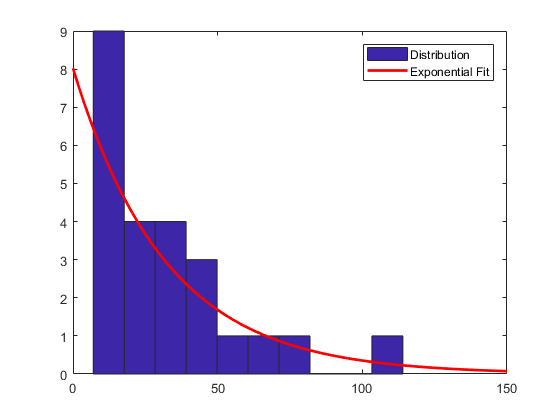
将常规参数模型与数据分布拟合的方法不在此部分的论述范围内。Statistics and Machine Learning Toolbox™ 软件提供用于计算分布参数的最大似然估计的函数。
可视化数据
- 概述
- 二维散点图
- 三维散点图
- 散点图数组
- 浏览图形中的数据
概述
您可以使用多种 MATLAB 图形来可视化数据模式和趋势。此部分介绍的散点图有助于可视化不同十字路口的流量数据之间的关系。数据浏览工具用于在图形上查询各个数据点,并与数据点进行交互。
注意
此部分继续执行汇总数据中的数据分析。
二维散点图
二维散点图使用 scatter 函数创建,用于显示前两个十字路口的流量之间的关系:
load count.datc1 = count(:,1); % Data at intersection 1c2 = count(:,2); % Data at intersection 2figure
scatter(c1,c2,'filled')
xlabel('Intersection 1')
ylabel('Intersection 2')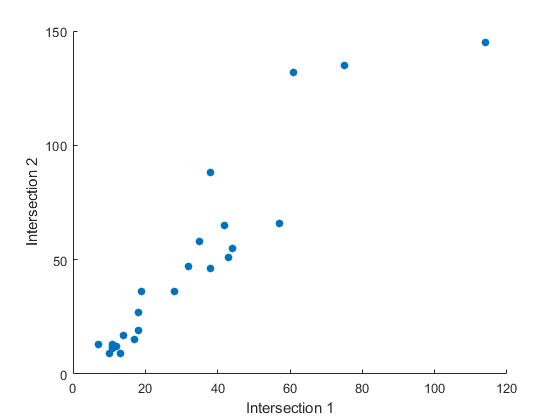
使用 cov 函数计算的
协方差计算两个变量之间的线性关系强度(数据在散点图中沿着最小二乘直线排列的松紧度):
C12 = cov([c1 c2])
C12 = 1.0e+03 * 0.6437 0.9802 0.9802 1.7144
结果以对称的方阵形式显示,并在第 (i, j) 个位置中显示第 i 个和第 j 个变量的协方差。第 i 个对角线元素是第 i 个变量的方差。
协方差的缺点是:取决于度量各个变量所使用的单位。您可以将变量的协方差除以标准差,以将值归一化为介于 +1 和 –1 之间。corrcoef 函数计算
相关系数:
R12 = corrcoef([c1 c2])
R12 = 1.0000 0.9331 0.9331 1.0000
r12 = R12(1,2) % Correlation coefficient
r12 = 0.9331
r12sq = r12^2 % Coefficient of determination
r12sq = 0.8707
由于已经过归一化,因此相关系数的值可以方便地与其他成对的十字路口的值相比较。相关系数的平方(即
决定系数)是最小二乘直线的方差除以均值方差的结果。因此,它与响应(在本示例中为第 2 个十字路口的流量)中的方差成比例,在散点图中,该方差已被清除,或者用最小平方直线以统计方式说明。
三维散点图
三维散点图使用 scatter3 函数创建,用于显示所有三个十字路口的流量之间的关系:使用在上述步骤中创建的变量 c1、c2 和 c3:
figure
c3 = count(:,3); % Data at intersection 3scatter3(c1,c2,c3,'filled')
xlabel('Intersection 1')
ylabel('Intersection 2')
zlabel('Intersection 3')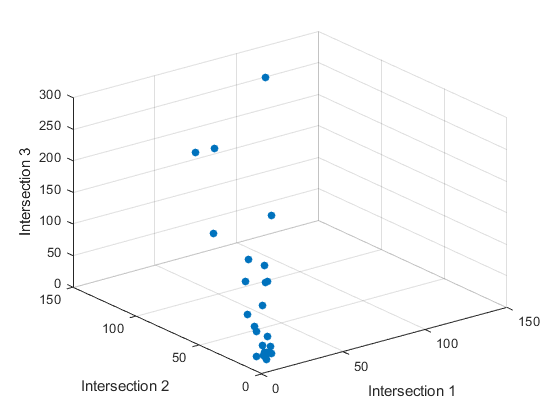
通过使用 eig 函数计算协方差矩阵的特征值来度量三维散点图中的变量之间的线性关系强度。
vars = eig(cov([c1 c2 c3]))
vars = 1.0e+03 * 0.0442 0.1118 6.8300
explained = max(vars)/sum(vars)
explained = 0.9777
特征值是基于数据的
主分量的方差。变量 explained 度量数据轴上第一个主分量说明的方差的比例。与二维散点图的决定系数不同的是,此度量会区分预测器和响应变量。
散点图数组
使用 plotmatrix 函数比较多对十字路口之间的关系:
figure plotmatrix(count)
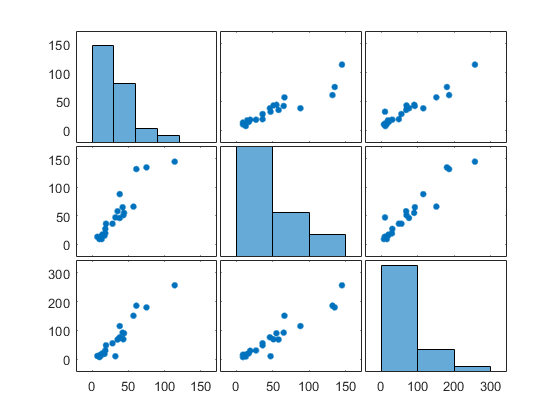
位于数组第 (i, j) 个位置的绘图是一个散点图,第 i 个变量位于纵轴上,第 j 个变量位于横轴上。第 i 个对角线位置的绘图是第 i 个变量的直方图。
浏览图形中的数据
使用图窗工具栏中的两个工具,您可以通过鼠标选取几乎任何 MATLAB 图形中的观测值:
- 数据游标
- 数据刷亮


上述每个工具都会使您置于探索模式,在此模式下,您可以在图形上选择数据点以便确定其值,并创建工作区变量来包含特定观测值。当使用数据刷亮时,您还可以复制、删除或替换所选观测值。
例如,绘制 count 的第一列和第三列的散点图:
load count.dat scatter(count(:,1),count(:,3))
选择数据游标工具
,然后点击最右侧的数据点。此时将在该处显示说明该点的 x 和 y 值的数据提示。
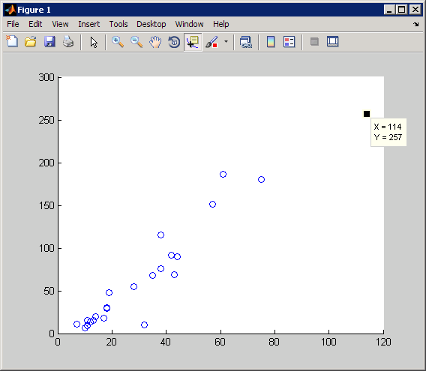
默认情况下,数据提示显示 x、y 和 z(适用于三维绘图)坐标。您可以将数据提示从一个数据点拖至另一个数据点以便查看新值,或者通过右键点击数据提示并使用上下文菜单来添加其他数据提示。此外,还可以使用 MATLAB 代码自定义数据提示显示的文本。
数据刷亮是一个相关功能,用于通过点击或拖动在图形上高亮显示一个或多个观测值。要进入数据刷亮模式,请在图窗工具栏上点击“数据刷亮”工具
左侧。点击此工具图标右侧的箭头会显示一个调色板,用于选择刷亮观测值所使用的颜色。此图窗显示的散点图与上一图窗相同,但超过均值一个标准差的所有观测值(使用工具 > 数据统计信息 GUI 确定)刷亮为红色。
scatter(count(:,1),count(:,3))
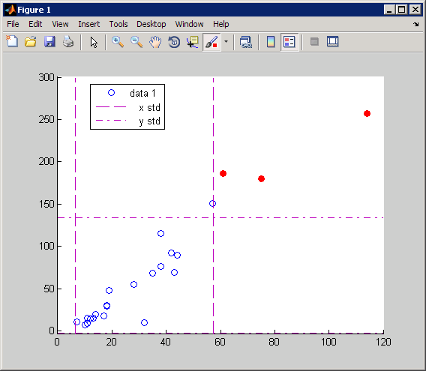
刷亮数据观测值之后,可以对数据观测值执行下列运算:
- 删除数据观测值。
- 将数据观测值替换为常量值。
- 将数据观测值替换为 NaN 值。
- 将数据观测值拖动、复制并粘贴到命令行窗口。
- 将数据观测值另存为工作区变量。
例如,使用“数据刷亮”上下文菜单或工具 > 刷亮 > 新建变量选项创建一个名为 count13high 的新变量。
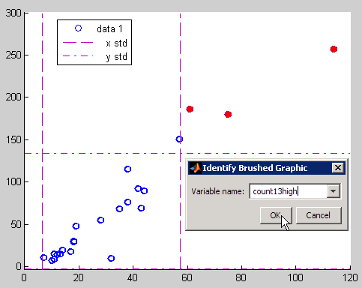
此时将在工作区中生成一个新变量:
count13high count13high = 61 186 75 180 114 257
链接图或数据链接是一个与数据刷亮紧密相关的功能。如果绘图实时连接到所描绘的工作区数据,则此绘图已链接。对于存储在对象的 XData、YData(以及 ZData,如果适用的话)中的变量副本,当所链接的工作区变量发生更改或被删除时,这些变量副本会自动更新。这会导致显示这些副本的图形自动更新。
通过将绘图链接到变量,您可以通过观测值的不同表示形式来跟踪特定观测值。当刷亮链接图中的数据点时,刷亮一幅图形会高亮显示链接到相同变量的所有图形中的相同观测值。
数据链接建立图窗和工作区变量之间的即时双向通信,通信方式与“变量编辑器”和工作区变量之间的通信方式相同。通过在图窗的工具栏上激活“数据链接”工具

可以创建链接。激活此工具后,绘图顶部会显示下图中显示的“链接图”信息栏(可能会遮住绘图标题)。您可以消除此信息栏(如下图所示),而不必取消链接绘图;此信息栏不会被打印,并且不会随图窗一起保存。
下面两幅图形描绘在刷亮左侧图形中的某些观测值之后链接数据的散点图显示。常见变量 count 将刷亮标记携带到右图。即使右图未处于数据刷亮模式,它也会显示刷亮标记,因为它链接到其变量。
figure
scatter(count(:,1),count(:,2))
xlabel ('count(:,1)')
ylabel ('count(:,2)')
figure
scatter(count(:,3),count(:,2))
xlabel ('count(:,3)')
ylabel ('count(:,2)')同左图相比,右图表明刷亮的观测值线性关系更加密切。
当在“变量编辑器”中显示这些变量时,刷亮数据观测值以刷亮颜色高亮显示,如此处所示:
openvar count
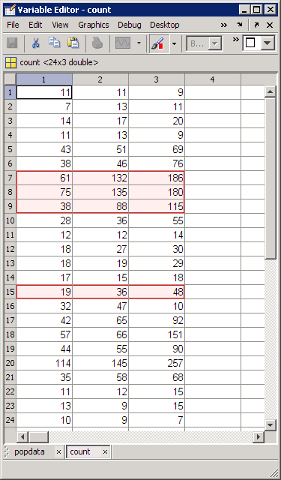
在“变量编辑器”中,可以更改链接的绘图数据的任何值,并且图形将反映所做的编辑。要刷亮“变量编辑器”中的数据观测值,请点击其“刷亮工具”
按钮。如果链接图当前描绘了刷亮的变量,刷亮的观测值将在链接图和“变量编辑器”中高亮显示。当刷亮作为矩阵中的某个列的变量时,还会刷亮该行中的其他列。也即,可以刷亮行或列向量中的各观测值,但矩阵中的所有列都会在刷亮的任何行中高亮显示,而不是仅高亮显示您点击的观测值。
数据建模
- 概述
- 多项式回归
- 一般线性回归
概述
参数模型将对数据关系的理解转换为具有预测能力的分析工具。对于流量数据的上升和下降趋势,多项式模型和正弦模型是理想选择。
多项式回归
使用 polyfit 函数估计多项式模型的系数,然后使用 polyval 函数根据预测变量的任意值评估模型。
以下代码使用 6 次多项式模型拟合第三个十字路口的流量数据:
load count.datc3 = count(:,3); % Data at intersection 3 tdata = (1:24)';
p_coeffs = polyfit(tdata,c3,6);
figure
plot(c3,'o-')
hold on tfit = (1:0.01:24)';
yfit = polyval(p_coeffs,tfit);
plot(tfit,yfit,'r-','LineWidth',2)
legend('Data','Polynomial Fit','Location','NW')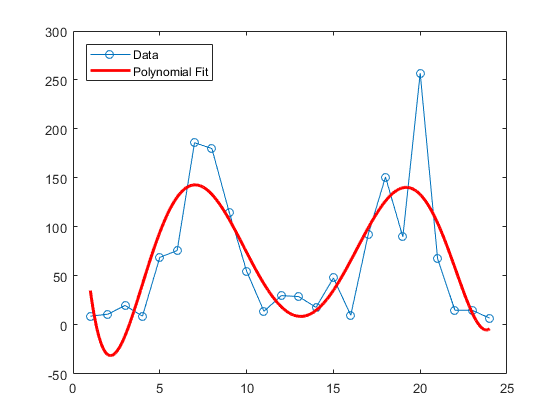
此模型的优点是可以非常简单地跟踪升降趋势。但是,此模型的预测能力可能有欠准确性,特别是在数据两端。
一般线性回归
假定数据是周期为 12 个小时的周期性数据,并且峰值出现在第 7 个小时左右,拟合以下形式的正弦模型是合理的:
y=a+bcos((2π/12)(t−7))
系数 a 和 b 呈线性关系。使用 MATLAB® mldivide(反斜杠)运算符拟合一般线性模型:
load count.datc3 = count(:,3); % Data at intersection 3 tdata = (1:24)';
X = [ones(size(tdata)) cos((2*pi/12)*(tdata-7))];
s_coeffs = Xc3;
figure
plot(c3,'o-')
hold ontfit = (1:0.01:24)';
yfit = [ones(size(tfit)) cos((2*pi/12)*(tfit-7))]*s_coeffs;
plot(tfit,yfit,'r-','LineWidth',2)
legend('Data','Sinusoidal Fit','Location','NW')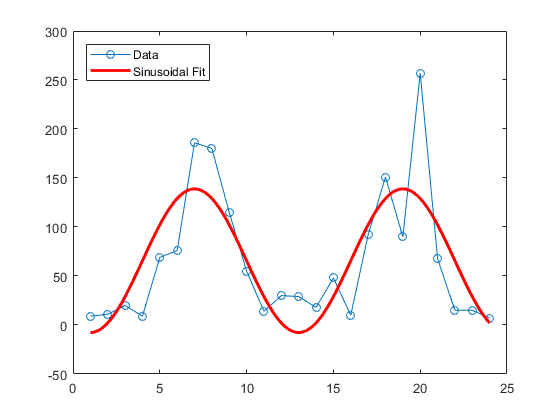
使用 lscov 函数计算拟合时的统计信息,例如系数的估计标准误差和均方误差:
[s_coeffs,stdx,mse] = lscov(X,c3)
s_coeffs = 65.5833 73.2819
stdx = 8.9185 12.6127
mse = 1.9090e+03
使用周期图(用 fft 函数计算)检查数据周期是否假定为 12 小时:
Fs = 1; % Sample frequency (per hour)n = length(c3); % Window lengthY = fft(c3); % DFT of dataf = (0:n-1)*(Fs/n); % Frequency rangeP = Y.*conj(Y)/n; % Power of the DFTfigure
plot(f,P)
xlabel('Frequency')
ylabel('Power')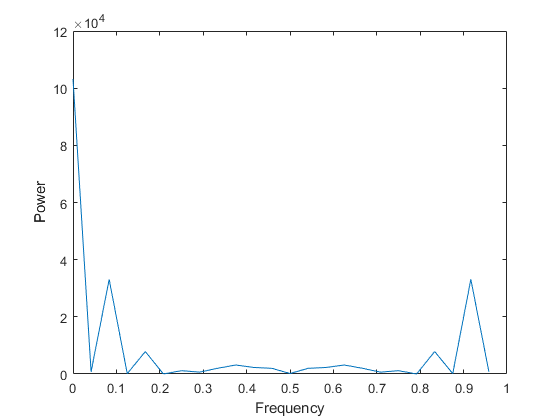
predicted_f = 1/12
predicted_f = 0.0833
0.0833 附近的峰值证明此假定是正确的,虽然其出现频率稍微高一点。可以依此相应调整此模型。
相关推荐
matlab低通滤波器函数怎么用(揭晓低通滤波器函数应用方法)
1 预备知识 2 simulink 仿真 3 simulink 运行结果 4 matlab 实现 5 matlab 运行结果 6 C 语言实现 7 C 语言运行结果 1 预备知识 …
matlab2018安装教程(免费分享其安装流程图)
今天给大家分享Matlab2018a的安装方法,一步一步的截图,只适合在WIN7和WIN8.1和WIN10系统下面安装哦,以下步骤全是现场截屏,亲测有效,欢迎收藏和分享,有不懂的,…
matlab怎么导入数据运行代码(分享matlab操作导入的教程)
比如,我们用Matlab对数据进行分析处理之后,需要将其结果保存下来,方便后续查看或继续分析,这时候就需要将这些数据先保存到文件中(如txt)。 1、保存数据到txt中 保存数据到…
matlab矩阵维度不一致怎么办(Matlab矩阵的简单操作)
还在为选择困难症而犯愁吗?想知道如何用MATLAB进行矩阵的运算操作吗?今天小编为大家带来“决策矩阵在MATLAB中的基础操作”,一起来看看吧! ⚡ 多图预警!建议连接WIFI阅读…
matlab画三维曲面的参数方程(怎么绘制三维图像)
MATLAB教学视频,零基础通用入门类:本期视频时长约80分钟,通过具体的绘图案例,详细地讲解了在MATLAB中如何实现三维曲线和三维曲面的绘制;深入解析了绘制三维网格图和三维曲面…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。