
前几天,我手里的一个项目需要将富文本的所有 html 标签全部删除,得到纯文本后再存储到数据库中。在一系列得搜索操作之后,我找到了实现这个目的的几种方法,在这里我分享给大家,当你遇到同样的情况兴许也能用的上。
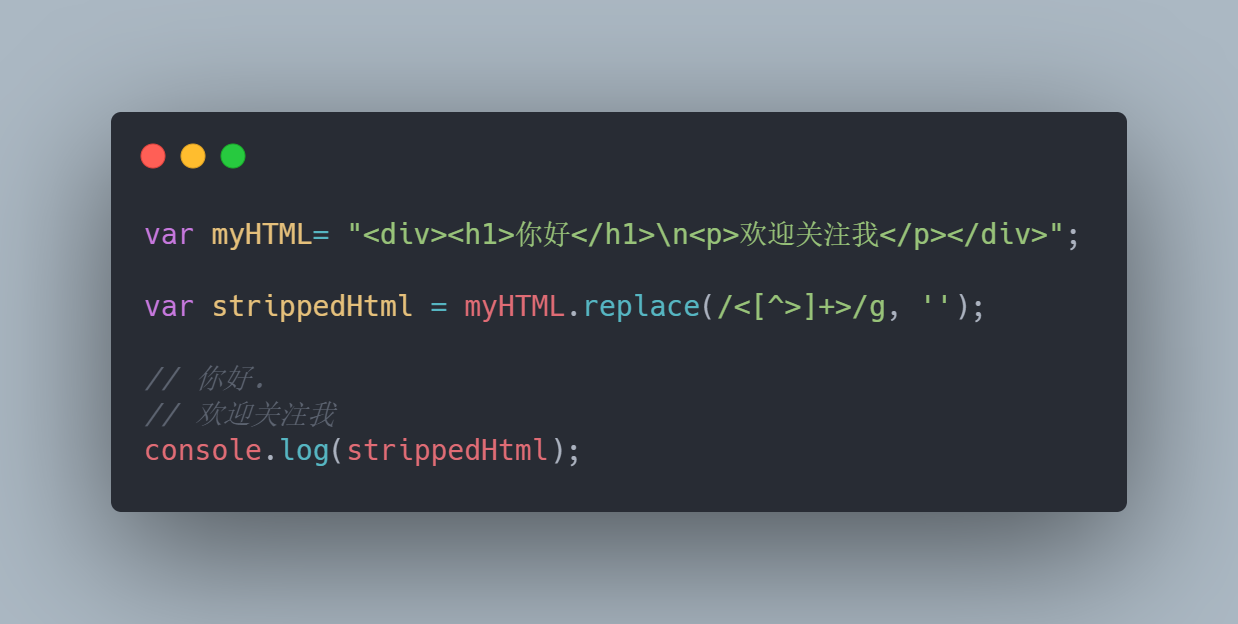
1. 使用 .replace(/<[^>]*>/g, ”)
这个方法是从文本中去除 html 标签最简单的方法。它使用字符串的方法 .replace(待替换的字符串,替换后的字符串) 将 HTML 标签替换成空值。 /g 是表示替换字符串所有匹配的值,即字符串中所有符合条件的字符都将被替换。
这个方法的缺点是有些 HTML 标签不能被剔除,不过它依然很好用。

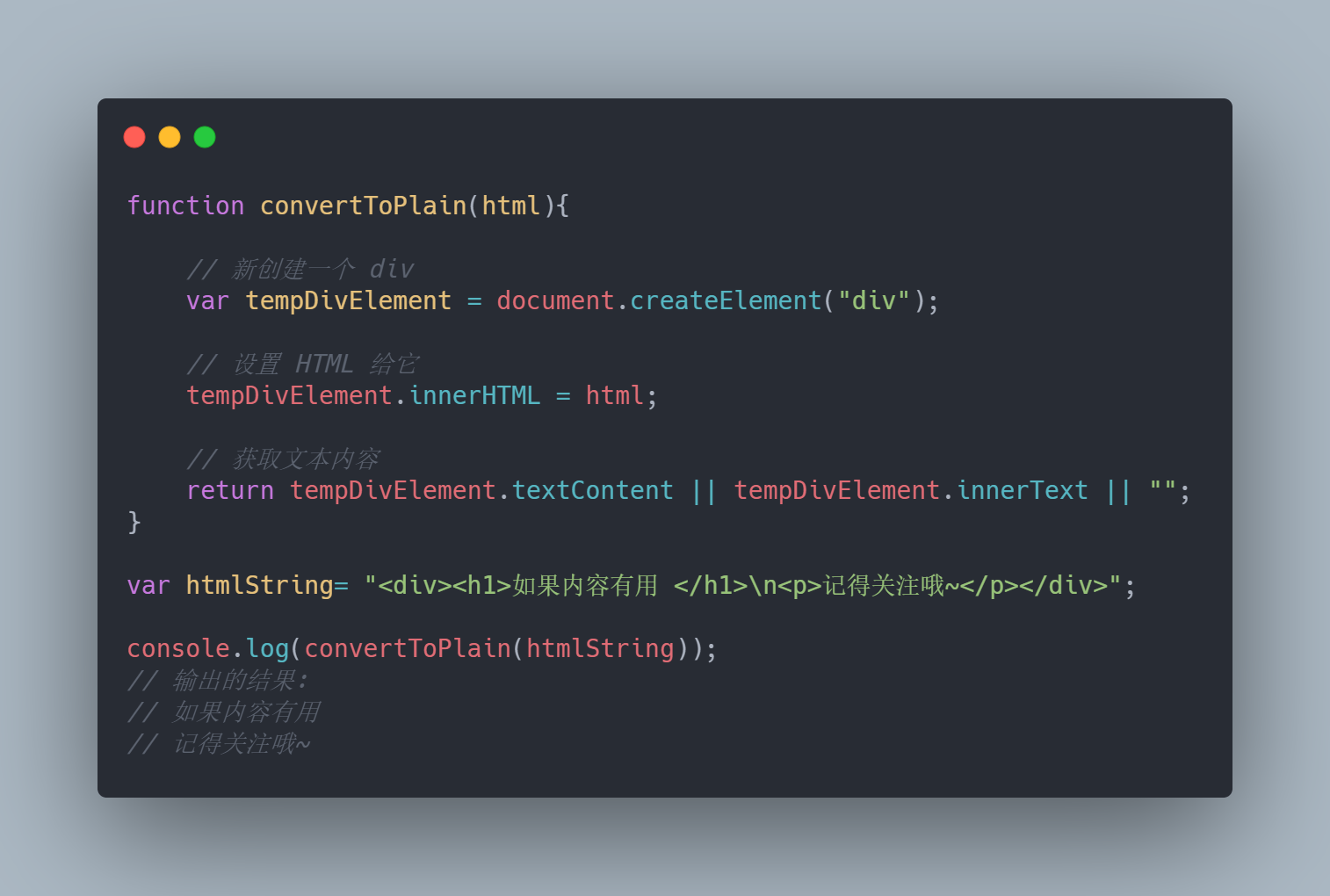
2. 创建临时DOM元素并获取其中的文本
这种方法是完成该问题的最有效的方法。创建一个临时 DOM 并给他赋值,然后我们使用 DOM 对象方法提取文本。
3. 使用 html-to-text npm 包
html-to-text 这个包的功能很全了,转换也有许多的选项比如:wordwrap, tags, whitespaceCharacters , formatters 等等。
安装:
npm install html-to-text使用:

相关推荐
电脑word文档打不开怎么办(附:4种解决办法)
word文档软件相信大家都不会陌生,我们电脑的系统一般都自带有word软件。在平常的办公工作中word软件成为不少朋友必须要用到的软件之一,其中我们在使用office中的word文…
怎么制作超链接,Word制作超链接的三种方法
简介:超链接是超级链接的简称。按照使用对象的不同,超链接分为:文本超链接,图像超链接,E-mail链接,锚点链接,多媒体文件链接,空链接等。Word文档中插入超链接有三种方式 工具…
微信聊天记录导出word的方法有哪些,聊天记录批量导出技巧
iPhone是苹果公司旗下研发的智能手机系列,它搭载苹果公司研发的iOS手机作业系统,很多朋友不知道苹果手机微信聊天记录如何导出到Word,下面让我们一起来学习一下吧。 方法/步骤…
超链接怎么弄,Word插入超链接方法
如何在Word中设置超链接? 作者:王士刚 如下图所示为某公司编写的变压器各系列产品详细说明的教案,由于这份文档有几百页,为了方便公司领导审阅,编写者希望在文档中从一个位置(图1A…
pdf文件转换word文件格式不变的2种方法!
在我的工作中经常会处理各种文件,其中最让人头痛的就是PDF文件,PDF格式因其不可编辑性着实令人不少人感到头痛,那么今天在这里为大家分享两种PDF转Word小技巧,帮你快速转换PD…
微信记录怎么导出,微信聊天记录导出word教程
前几天,我的朋友问我有没有办法把自己的微信支付账单导出来,因为她发现自己最近突然花掉了好多钱,却又不知道花在了哪里,所以想查查自己最近花掉的钱,不然她的理财状况怕是会越来越糟糕。然…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。