
得到 APP 是一个三年多的产品,最初采用纯 Native 的方式开发,在 18 年初,我们开始了 Hybyid 开发技术方案的探索和实践, 目前得到 APP 共包含了 ReactNative 和 Webview 两套 Hybrid 方案。本文从时间维度上,重点回顾一下 Webview Hybrid 方案在得到 APP 从 0 到 1 的过程,也希望我们的经历可以给一些想落地 Hybrid 方案的团队一点启发。
1. 背景和动机
得到是一个重运营场景的产品,APP 内大部分的功能都会有分享功能。18 年初时,开发一个功能,基本需要三端三个人。部分业务使用了内嵌 Webview 、类浏览器式的方案,虽然满足了跨端,但体验较差。所以最初的目的是希望有一套跨平台方案,一套代码可以三端执行,并且有较好的体验,这是当时 Hybrid 的架构图:


除了 Webview,当时较为流行的跨平台方案主要是 ReactNative、Weex,对比了两个方案,Weex 较为接近我们团队的技术栈,而 RN 当时社区较为成熟,最终我们认为社区更重要一些,所以选择了 RN。
在 RN 调研阶段,我们发现 RN 虽然支持三端和动态更新,但是需要配套的基础设施才可以实现其动态更新的能力,因此我们需要一个离线资源的管理系统,能够动态更新客户端内部的 RN 文件,而我们在思考和设计这个离线资源管理系统时,发现同样的思路可以应用于 Webview,我们可以把前端代码打成离线包,通过离线资源管理系统进行更新,而 Weview 在启动过程中,仅需要访问数据 API 而不需要下载 HTML/JS/CSS 等,也算是变相的增加了离线能力。
因此,我们制定了最初的 Roadmap:
- 先开发离线资源管理系统;
- 完成之后接入 Web 离线包,因为 Web 离线包开发成本较低,可以快速的改善现有项目的体验,快速收益;
- 最后在进行 RN 的开发和接入;
2. 离线资源包管理系统-Seeder
做一个技术驱动的项目就像是做一个产品,需要先梳理清楚需求、使用场景等,再想思考技术架构和实现细节。我们首先为项目起了个名字,叫 Seeder。(为什么起这个名字,其实没什么意义,主要是内部没有其他系统叫 Seeder。。。)
2.1. 目标
通过梳理,我们认为 Seeder 需要达成以下目标:
- 可以动态更新资源;
- 可以支持非最新版客户端进行更新;
- 支持增量更新;
- 支持多频道发布;
2.2. 技术选型和架构
明确目标后,我们要做技术选型和架构,在技术选型上,我们使用团队熟悉的 Nodejs+Mongodb 组合,架构图如下:
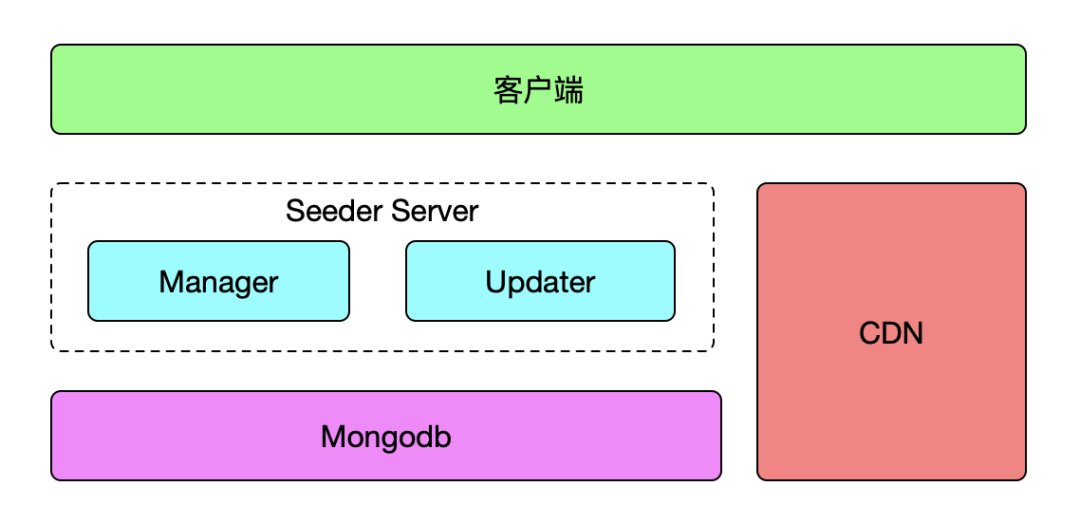
服务端包含 Seeder 和 CDN 两部分,CDN 部分主要是用来承接资源包的下载。Seeder 则拆分为 Updater 服务和 Manager 服务:
- Updater 服务:主要是承接处理客户端的更新请求;
- Manager 服务:主要进行资源包及相关配置的管理,包括生成 diff 包等等;
通过合理的拆分,Updater 服务在我们后续的压力测试中,2 台 8C16G 机器可以稳定承载 6000QPS;
2.3. 关键实现点 – Package 定义
既然是对资源包进行管理,我们需要定义资源包的格式和约束。
格式方面,我们选择了 tgz 格式,即使用 tar 进行归档,用 gzip 进行压缩的格式,以减少传输体积。
文件结构方面,在原有资源目录结构下的根目录,增加了一个 info.json 格式的文件,用来描述包的信息。

- appId:标示包的应用 ID;
- version:标示这个包的版本;
- depend.containerVersion: 标示这个包依赖的容器版本,目前的容器只有客户端;
- files: 一个数组,记录所有的文件和路径及其 MD5;
- meta: 扩展信息字段,这里使用了两个扩展字段,后面详细讲这两个字段
- type:包的类型
- routes:包需要注册的路由列表
2.4. 关键实现点 – 增量更新
增量更新指的是我们只需要下载一个 Patch 包,安装 Patch 包之后即可以完成应用的更新,像我们常用的 VSCode 之类的软件、大部分手机游戏,都支持增量更新。实现增量更新关键点是增量算法,通过调研,最终选择了支持二进制 diff 算法 bsdiff 。
确认算法之后就要开始思考增量包的实现方式,因为 bsdiff 是对单个二进制进行 diff,而我们是一个包。因此有两种方式:
- 基于归档压缩完的 tgz 包进行 diff 和 patch,这种方案的优势是实现成本低,带来的问题是客户端必须保留一份底包,并且由 于 Package 在客户端是下载完先解压才能执行,这种方案无法连续 patch 升级(不能增量从 v1.0->v1.1->v1.2,只能 v1.0->v1.1,v1.0->v1.2);
- 基于单文件 diff,即增量包其实包含多个 patch 文件,包含了描述 Package 变更信息的文件,这种方案虽然实现会复杂些,但是并没有方案 1 的各种问题,因此我们采用了是单文件 diff 的方案;
下面我们看下单文件 diff 的方案,先看一个增量包的结构:

相较于普通包,多了一个 update.json 文件,这个文件描述了整个包是如果变化的,基于这个文件和包内的其他文件,便可以 Patch 到最先的版本,看一下 update.json 的结构:
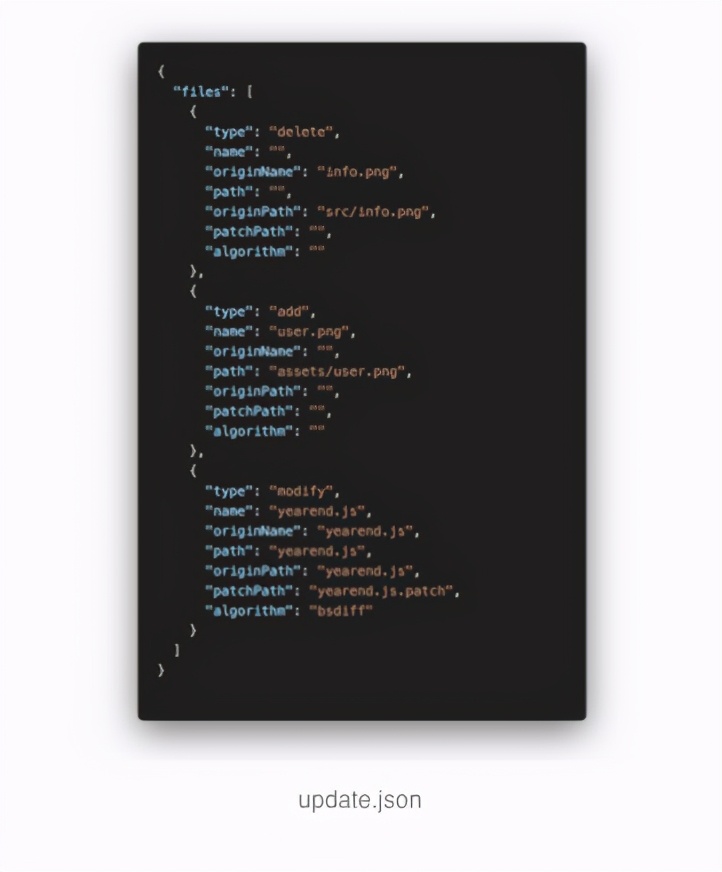
files 是描述变化的文件。关键字段 type, 标示了变更类型,add、delete、move、modify 等,分别表示新增的、需要删除的、发生目录和文件名变化的、内容变化的文件。add、delete、move 只涉及到了文件的新增、删除、变更路径等操作,而 modify 则是用到了 bsdiff,表示这个文件发生变化,需要增量更新。
通过这种精细化的操作,可以提高 patch 的效率,同时客户端无需保留底包,基于解压完的代码文件就可以完成增量更新。
梳理完了增量包结构,还有面临一个问题,就是增量包的生成时机。同样有两种方案:
- 请求来了生成增量包,好处就是一定会有增量包,问题是增量包的生成是一个 CPU 密集型操作,无法支持高并发;
- 提前生成增量包,但是只能提前生成指定版本数量的增量包,但可能存在较老版本没有增量包可用;
我们最终采用了提前生成增量包的方案,因为包内容差异越大,增量带来的收益越小,没有必要生成所有版本的增量包。我们在上传包时,会同时生成历史 10 个版本的增量包。基于我们目前的更新频率,10 个历史版本目前基本可以满足需求(后续不满足可以调整,就是一个配置项)。当然,用户长时间不打开 APP,可能再次打开,我们已经更新了十几个版本,这个时候只能通过全量包来进行更新。
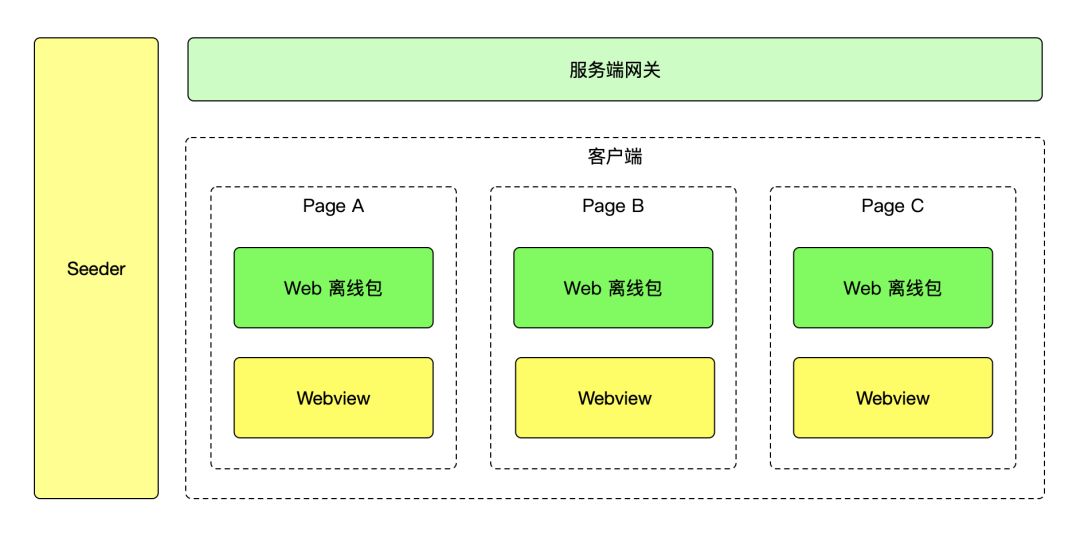
2.5. 架构变化
看一下我们调整后的架构变化:
3. 应用框架 – Adam
完成了基础设施的建设之后,客户端的离线资源也具备的动态更新的能力,但普通的 Web 离线包还有以下的限制:
- 每个 Webview 只能有一个页面,无法实现复杂的功能(为了跟客户端保持一致的页面交互体验,每个 Webview 只有一个页面,这样前进后退、导航条的表现是一致的);
- 无法控制导航条,一些需要定制导航条的功能依赖客户端;
- 没有体系化的框架,无法统一处理异常、缓存等;
为了解决以上问题,我们决定开发一个应用层的框架。
3.1. 目标和分解
我们整个团队最熟悉的技术栈是 Vue,因此 Adam 肯定是基于 Vue 做封装,在设计 Adam 之前,需要我们先确认目标:
- 功能上:一个 Package 可以作为一个完整的 Application,能够完整地实现一个功能模块,包括多页面的功能等;
- 技术上:实现标准化的解决方案,由框架处理缓存、异常页面等通用逻辑;
对目标进一步做分解:
- 需要客户端将界面全部交给 Webview 处理;
- 需要 Router,并且像客户端一样,支持栈式管理页面的路由;
- 页面要实现客户端相同的前进和后退动效,要支持滑动返回上一个页面;
- 需要抽象缓存和异常页面等到框架层;
3.2. 架构图
我们先看下一下 Adam 的整体架构,以便于我们后续内容的表述:
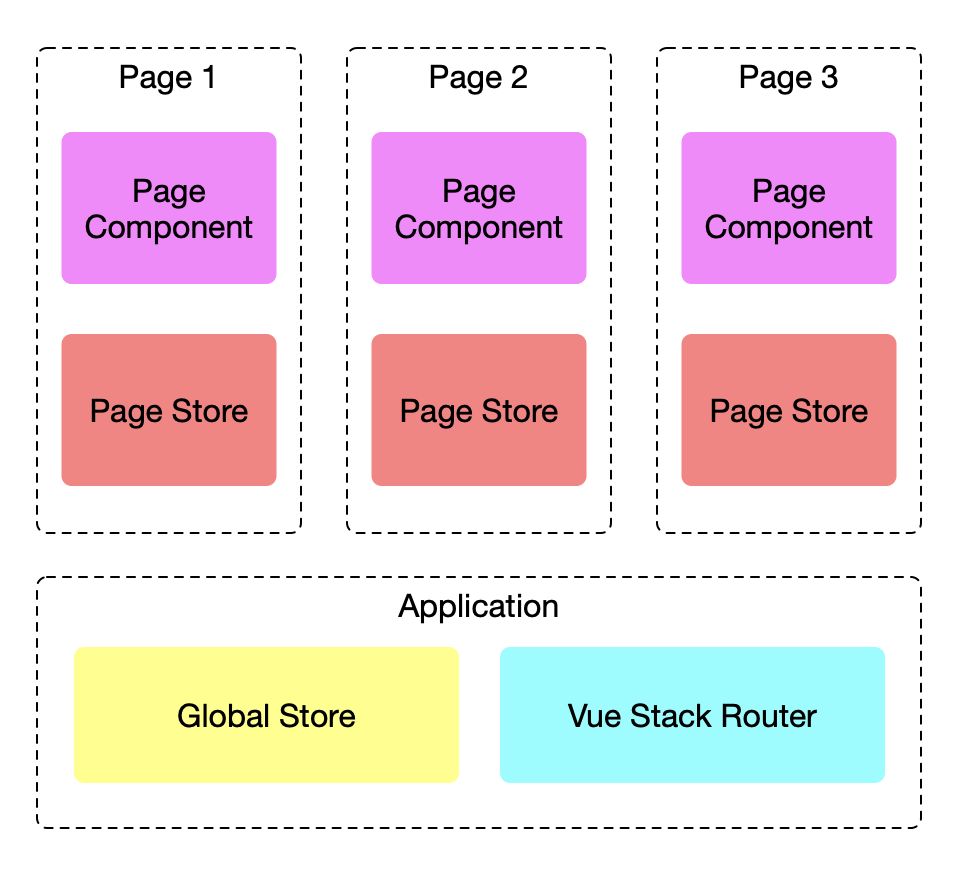
每一个 Web Package 就是一个应用,每个 Application 实例对应一个 Global Store 和 vue-stack-router 的实例,对应多个 Page 实例。
每一个页面都由 Page Componets 和 Page Store 组成。其中 Page Store 的生命周期跟页面保持一致。
3.3. 关键实现点 – Router
最初的 Router 方案我们是选了我们常用的 vue-router,但在实现过程中,遇到了以下问题:
- 实现类似栈式的路由较为困难。客户端内的页面大部分都具有栈式的特点,页面实例的存活取决于是否在栈中。而 vue-router 中,组件实例的存活则是取决与是否使用了 kee-alive 组件;
- 实现两个页面间的、类似 Native 的滑动返回较为困难;
- 无法实现多例页面。Native 中,A 页面跳转 A 页面,会产生一个新的 A 页面的实例。vue-router 中,A 页面跳转 A 页面会重新渲染现有的 A 页面,也就是 A 页面始终是单例的;
为了解决这些问题,我们开发了 vue-stack-router (已开源,具体实现细节,感兴趣的可以直接看 github 代码,内容较多,这里不展开),相较于 vue-router,有以下新功能:
- 栈式的路由管理;
- 路由间数据传递;
- 支持更细粒度、可定制的路由过渡效果;
- 支持预渲染;
基于预渲染模式,我们实现了手势滑动返回的功能,即触发手势时,预渲染后一个页面,此时同时存在两个叠加在一起的页面,通过 JS 控制两个页面的动画,便可以实习类似 Native 的滑动返回的效果。
3.4. 关键实现点 – Store
提到状态管理工具,共识都是简单的项目无需使用 Store,复杂项目才能体现出 Store 的价值,其实无非是引入 Store 带来了成本。我们分析一下移动端页面的特点:
- 展示为主
- 页面间耦合性低
- 数据流简单
因此,在移动端页面,我们追踪状态变化的收益可能不会很高,如果去掉状态追踪,Store 可以变的很精简, 看一下我们自己精简的 Store,原理如下:
classMyStore{
public name:string='';
public updateName(name:string):void{
this.name = name;
}
}
const store =Vue.observable(newMyStore());没有状态追踪,只是最精简的将状态抽离到一个类中进行管理。
聊完了 Store 实现,再看看关于 Store 的组织形态,我们常用 Vuex 和 Redux 都是单一组件树,连 MobX 也有 mobx-state-tree 这种单一组件树的社区方案。但是结合移动端业务的特点,单一组件树会有些问题,对多页面实例的支持,实现比较复杂。再一个,优秀的单一组件树的组织通常是跟页面分离的,经过单独设计的,因此会带来了额外的心智负担。
基于以上死牢,最后我们没有采用单一组件树,而是实现了多状态的 Store 方案:一个页面对应一个 Store,Store 和页面的生命周期保持一致的方案。逻辑跟展现分离,页面间又不耦合,最重要的是简单;
3.5. 缓存
数据缓存是体验优化的一大利器,通过先渲染缓存数据,在更新正式数据的方式,我们可以立刻展现出一个页面而无需等待。Adam 实现了三级缓存:
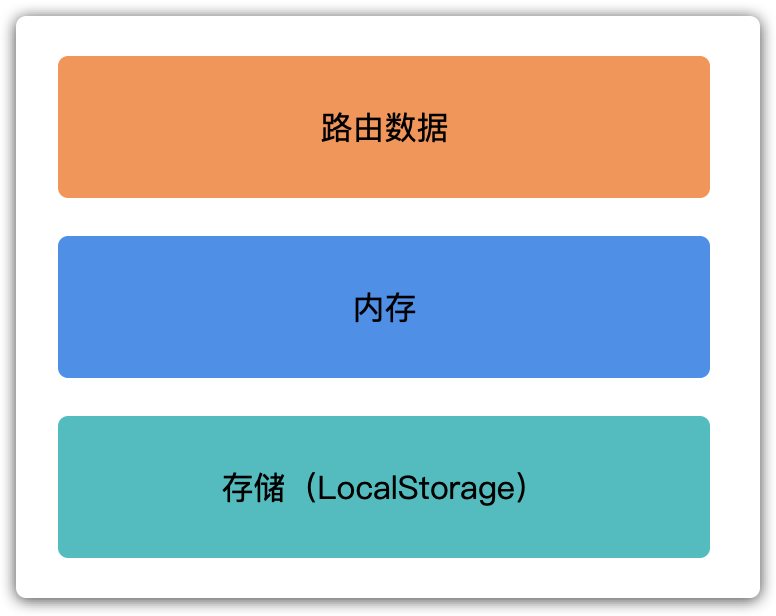
依次从路由数据、内存、LocalStorage 中取。路由数据是什么呢,通常在客户端内,页面跳转很多都是摘要信息跳往详情信息的页面(如列表的 item 跳详情页),其实前一个页面已经包含一部分后续页面的信息,这个时候可以将前一个页面的数据带到后一个页面中,后一个页面便可以渲染出主要信息,提升用户体验。
那么缓存的数据是哪里来的呢,并不需要开发者手动写入。我们知道 View=fn(State),在 Store 方案中我们已经将页面的状态都放到 store 中了,只需要缓存 Store 就可以了。至于缓存和还原的时机,就是在页面销毁时,我们序列化 Store,等页面在打开,还原 Store 。
4. 标准化容器
在开发 Adam 的同时,也不断有同学反馈,现在接入一个新的 Web Hybrid 业务比较麻烦,需要客户端配置 webview,而且新业务依赖发版,是不是可以我们完全不依赖客户端呢?
答案是可以的。
4.1. 路由协议
我们在 Package 中增加了包的类型和包的全局路由信息,这样客户端在更新到包的信息时,可以动态注册路由,也就是所有的 Package 中的路由,都绑定到一个标准化的 webview,webview 启动后,根据跳转过来的路由加载对应 Package,已实现动态加载和注册功能。
4.2. 最终架构
完成了 Adam 和 标准化容器后,我们看一下最终接架构:
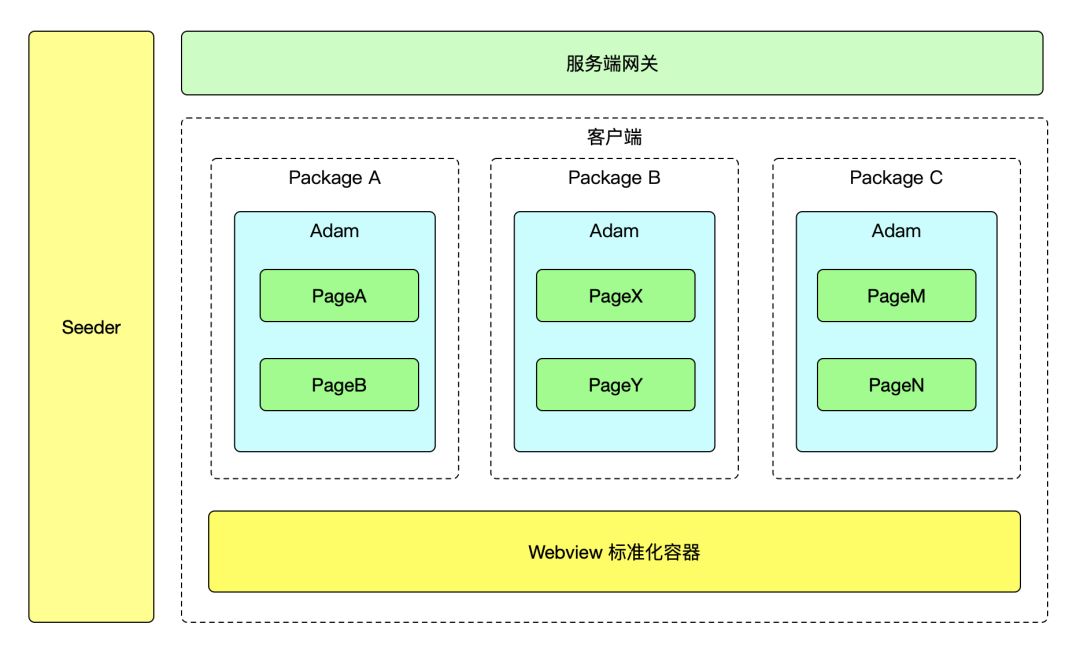
至此我们可以将每个 Package 当做一个独立的 Application 来更新和迭代。
5. 总结和思考
5.1. 成果
功能方面,我们接入了讲座、电子书、评测、训练营、得到大学、活动系统、帮助中心等模块,接入了 90+的页面(其中 ReactNative 占 30+,Web 占 60+);
效率方面,我们在一年半内支撑了 49 个功能模块动态更新了 1900 次。测试环境中,动态更新了 1.3 万次;
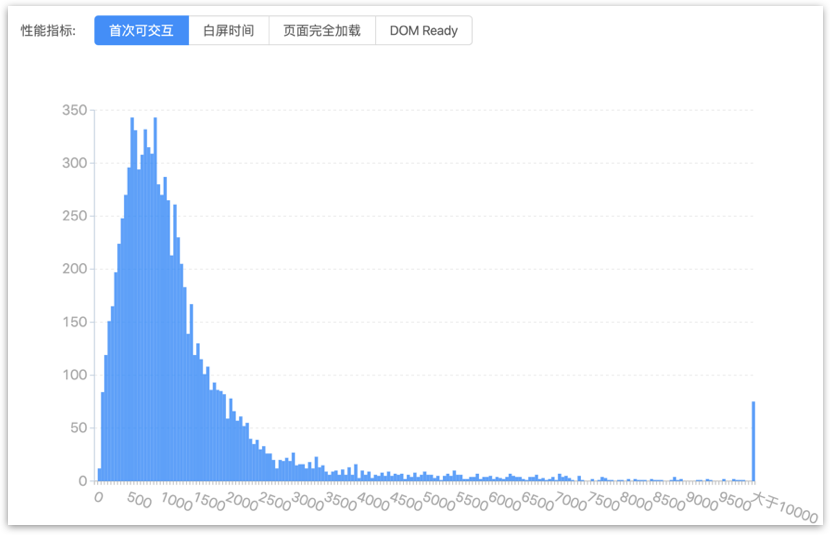
性能方面,我们从性能监控系统中找到两个未使用和使用 Seeder 的功能进行对比(这个对比不太严谨,因为没有同一个功能先后采用两种方案的数据,我们找了两个功能相近,代码量相近的两个项目进行对比)。
普通 Webview 方案
Adam + Seeder 方案:
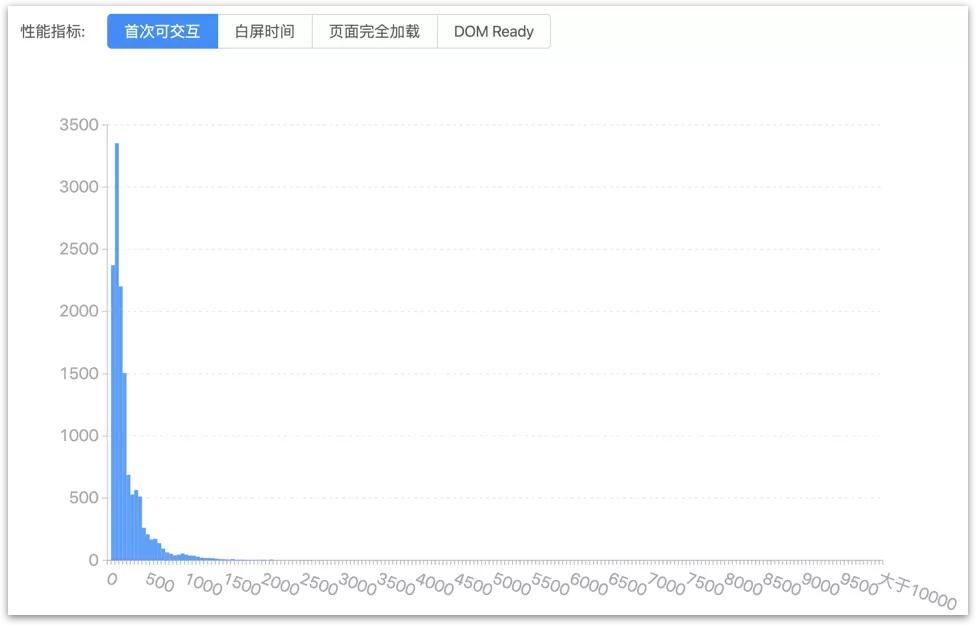
基本可以看到,稳定性和效率都有较好的改善。
5.2. 思考
Hybrid 落地过程中,我们踩了很多坑,也有很多收货,简单谈两点。
第一个,如何评价一个技术方案的好坏?我们有太多的标准:站在业务角度,是不是能满足需求及低成本的满足潜在的后续需求;站在运维角度,是不是带来了新的部署运维成本。站在技术角度,我们甚至可以掏出一本设计模式大谈一番。但是我们很少有注意到技术方案的用户体验,这里的用户指的是使用你框架、库的开发同学。站在业务开发同学的角度会发现,提供的方案确实解决了问题,但是使用这个方案过程中,可能有 30% 工作是不属于方案部分,但是属于方案部分必须的,比如方案的入参是 A,开发者需要花大力气才能得到 A,才能使用这个方案。所以作为框架、库的开发者,要考虑清楚整个方案的使用场景,技术部分是不是可以覆盖整个场景,覆盖不了要怎么解决,是否需要提供自动化工具等等。
第二个,Hybrid 不是一个端的事情,而是三端一起的事情,而作为推动方,要尽可能的了解三端,不了解可以多跟各端同学沟通交流,不要做成一方推动两方配合,要让大家感觉是在一起干一件事情,这样才能做好。
5.3 后续的规划
后续的规划主要是有两大方面:
- Adam 的多环境多端的支持,覆盖得到业务“端”的场景;
- Seeder 更加灵活的更新场景,比如支持 Lazy 加载等;
相关推荐
加速cdn效果好不好,cdn加速器的使用方法介绍
现在,越来越多的用户建站购买云服务器时,都会额外的购买CDN加速,网站使用CDN加速已经逐渐成为一种新的趋势。那么,为什么网站要使用CDN加速?CDN加速有什么作用呢?解决这个问题…
cdn网站加速哪个好,免费国外CDN加速器!
CDN是什么,其实CDN加速网站访问速度,提高网站服务器的运行效率,让用户更好的体验极速的访问体验。市面上好多CDN,比如360的网站安全卫士CDN加速,百度云CDN加速,阿里云C…
加速器模式区别,网易uu哪个模式稳定
在steam游戏爆火的现在,游戏加速器成为了玩家们必不可少的网络加速工具,那有多少人了解游戏加速器的原理,以及游戏加速器与VPN的区别呢? 一、什么是游戏加速器? 游戏加速器是针对…
全球网络加速器破解版下载,永久免费的加速器软件
最近,英国的数据众包公司 OpenSignal 发布了一份报告,报告中展示了 2017 年第一季度世界各国的 4G 下载速度排名。在榜单中,第一名的新加坡 4G平均下载速度为 45…
奇游网游加速器怎么样,加速器的收费标准及使用方法介绍
近日,奇游电竞加速器迭代焕新,新版6.0.9客户端带来贴心游戏预约功能以及多款游戏优化,游戏下载速度在原基础上再度提升,为你带来电竞级加速体验,游戏更加畅快。 更新一 预约你心仪的…
战地5用什么加速器比较好,战地5免费加速器介绍
EA制作发行的《战地5(BattlefieldV)》最近占尽了风头,《战地5》是一款第一人称FPS游戏,游戏营造出了真实的二战战场,史诗级的战役和多种武器载具的加入让玩家们大感兴趣…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。