
一、建立IP代理池的思路:
做爬虫时,遇到访问太频繁IP被封是难以避免的,而本地单个IP是不足以进行大规模爬取,并且自己并不想购买付费代理,那么,构建一个IP代理池是非常有必要的。思路如下: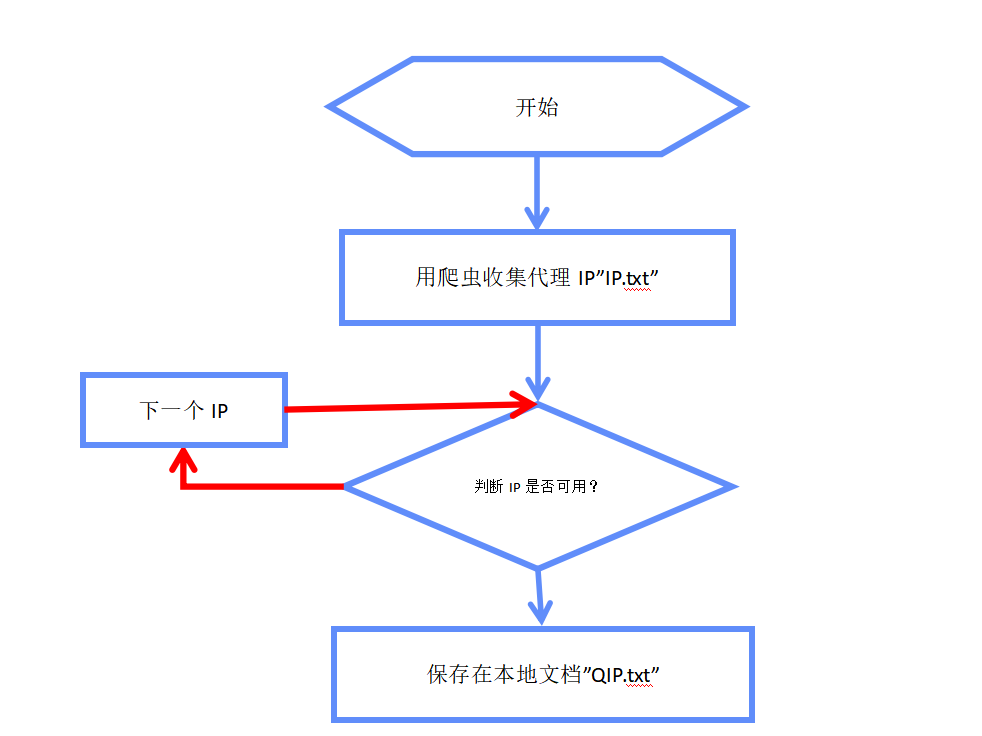

图1
二、建立IP 代理池的步骤:
- 爬取代理IP:搜索选择代理IP网站,选取免费代理;代码如下:
# _*_ coding:UTF-8 _*_
# 开发作者:Jason Zhang
# 创建时间:2020/12/29 17:58
# 文件名称:爬取代理IP.PY
# 开发工具:PyCharm
import requests
import lxml.html
import os
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url_list = ['http://www.xicidaili.com/nn/%r' % i for i in range(1,10)]
ip_list = []
for url in url_list:
r = requests.get(url,headers=headers)
etree = lxml.html.fromstring(r.text)
ips = etree.xpath('//tr[@class="odd"]')
for ip in ips:
IP = ip.xpath('//td/text()')
ip = IP[0] +':'+ IP[1]
ip_list.append(ip)
f = open('ip.txt','wb')
f.write(','.join(ip_list).encode('utf-8'))
f.close(- 验证代理IP:
通过网络访问来验证代理IP的可用性和访问速度,将之前爬取到的代理IP地址从ip.txt文件中提取出来,分别试用代理IP去访问某个网站首页,仅保留响应时间在2秒内的IP,并保存在QIP.txt中,代码如下:
# _*_ coding:UTF-8 _*_
# 开发作者:关中老玉米
# 创建时间:2020/12/29 18:27
# 文件名称:验证代理IP.PY
# 开发工具:PyCharm
import requests
ip_list = open('ip.txt').read().split(',')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
q
url = 'https://www.baidu.com' #用百度来测试IP是否能正常连网
for i in ip_list: #设置超时时间timeout为2 s,超时则为不可用IP
r = requests.get(url, proxies={'http': 'http://' + ip[i]}, headers=headers,timeout=2)
if r.text:
qip.append(qip[i])
else:
continue
f = open('quality_ip.txt','wb')
f.write(','.join(quality_ip).encode('utf-8'))
f.close()- 使用代理IP:
建立IP代理池之后,有以下两种使用代理IP的方式。
# _*_ coding:UTF-8 _*_
# 开发作者:Jason Zhang
# 创建时间:2020/12/31 18:03
# 文件名称:使用代理IP.PY
# 开发工具:PyCharm
# (1)使用随机 IP,代码如下:
import random
import requests
ip_list = open('quality_ip.txt').read().split(',')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
url = 'http://*********'
r = requests.get(url, proxies={'http': 'http://'+random.choice(ip_list)},headers=headers)
# (2)因为免费的代理时效很短,在后续的爬取任务中很容易失效,所以当出现访问错误(响应码不等于 200)时,更换 IP,代码如下:
ip_list = open('qip.txt').read().split(',')
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
for ip in ip_list:
for i in range(len(url_list)):
r = requests.get(url_list[i], proxies={'http': 'http://'+ip},headers=headers)
if r.status_code != 200:
break相关推荐
云服务器哪家好(腾讯云、百度云、阿里云深度评测)
腾讯云是腾讯旗下的一家云服务品牌,阿里云是阿里粑粑旗下的一家云服务品牌,百度云是百度旗下的一家云服务品牌。 只要是想买云服务器的站长几乎都考虑过这三家云服务商的其中一家。而阿里云几…
什么叫服务器(服务器有什么用)
一、服务器的定义和作用如下: 1、服务器是一种高性能计算机,作为网络的节点,存储、处理网络上80%的数据、信息,因此也被称为网络的灵魂。 2、也可以这样讲,服务器指一个管理资源并为…
如何使用云存储服务器(快速搭建自己的云服务平台)
现在的路由器也开始智能起来,但是多数人还是用路由器当做信号接收发射转换装置,忽略了更多好玩的功能,写此篇文章的目的是:如果你也有一款能够共享文件的路由器,不要把这一功能浪费了这一功…
dns服务器有什么用(电脑设置DNS的方法)
不知道大家在设置路由器的时候,在WAN口设置里面会看到这样一个选项: 这里的DNS服务器是什么意思呢?我想可能大部分人都忽略了这点。那么今天就具体来说一下DNS服务器是什么?具体有…
国外代理服务器ip怎么使用(正确使用免费代理IP的方法)
相信大多数人看到“代理服务器”这几个字都是满脸懵逼的状态,但是如果笔者不和你聊代理服务器,而是说一说VPN与科学上网,相信你一定就会漏出会心的微笑了。今天,笔者就和大家聊一聊究竟什…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。