
网络上的一些文本,部分会有一些不必要的空格,如果想把空格全部替换掉,使用字符串string类的replace()方法即可,如:
str = str.replace(‘ ‘,”)
但如果是中英文混排的文本,如果想替换掉汉字中间的空格,而保留英文单词之间的空格,则问题的解决要复杂一些。需要用到正则表达式。
如有以下文档:
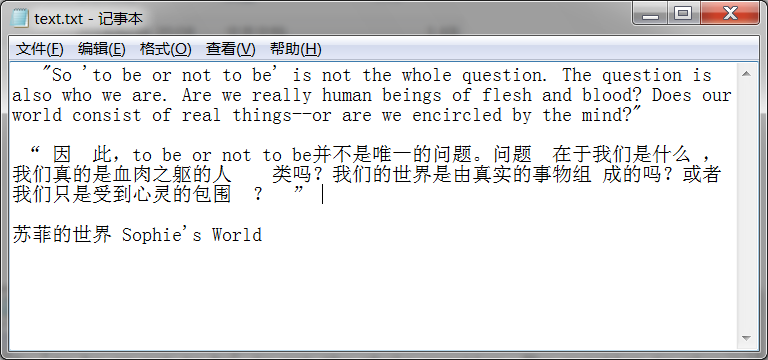
行(或段)的首尾、一些汉字之间有不必要的空格,需要替换掉。
用以下Python代码即可:


处理后的文本保存到了new.txt文档:
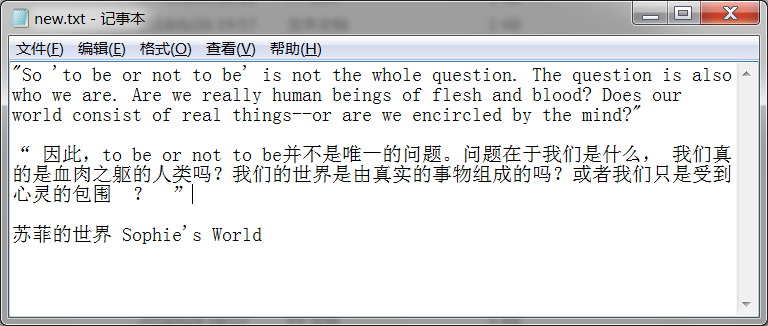

当然,一些有规律的乱码也可以处理。
上面有提到全部是中文的简单处理方法,也可以用一个简单的正则表达式判断文档或字符串内容是否包含“英文+空格+英文”的形式,然后用一个条件判断分别处理:


下面需要重点剖析一下上面关于正则表达式的概念及相关的一些内容:
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
1 compile()方法
向re.compile()传入一个字符串值,表示编译一个正则表达式,它将返回一个Regex 模式对象(或者就简称为Regex 对象)。
我们在Python中使用正则表达式时,re模块内部会做两件事情:
I 编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
II 用编译后的正则表达式去匹配字符串;
如果一个正则表达式要重复使用多次或一些较复杂的正则表达式,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配。编译后生成Regular Expression对象。
可以向re.compile()传入re.IGNORECASE 或re.I,作为第二个参数,让正则表达式不区分大小写:
>>> robocop = re.compile(r’robocop’, re.I)
>>> robocop.search(‘RoboCop is part man, part machine, all cop.’).group()
‘RoboCop’
2 r’……’的写法
r’……’表示忽略……可中可能存在的转义字符,当做普通字符看待;
3 中括号[]
有时候你想匹配一组字符,但缩写的字符分类(d、w、s 等)太宽泛。你可以用方括号[]定义自己的字符分类。
d、w 和s 分别匹配数字、字母和空格。
D、W 和S 分别匹配出数字、字母和空格外的所有字符。
例如,字符分类[aeiouAEIOU]将匹配所有元音字符(一个任意的元音字母),不论大小写。
Regex = re.compile(r'[aeiouAEIOU]’)
也可以使用短横表示字母或数字的范围。例如,字符分类[a-zA-Z0-9]将匹配所有小写字母、大写字母和数字。
请注意,在方括号内,普通的正则表达式符号不会被解释。这意味着,你不需要前面加上倒斜杠转义.、*、?或()字符。例如,字符分类将匹配数字0 到5 和一个句点。你不需要将它写成[0-5.],写成[0-5.]即可。
通过在字符分类的左方括号后加上一个插入字符(^),就可以得到“非字符类”。非字符类将匹配不在这个字符类中的所有字符。例如:
Regex = re.compile(r'[^aeiouAEIOU]’)
[abc]匹配方括号内的任意字符(诸如a、b 或c)。
[^abc]匹配不在方括号内的任意字符。
插入字符(^)还有另外一种用法,如果用在正则表达式的最前面,表明匹配必须发生在被查找文本开始处。类似地,可以再正则表达式的末尾加上美元符号($),表示该字符串必须以这个正则表达式的模式结束。如正则表达式r’d$’匹配以数字0 到9 结束的字符串。可以同时使用^和$,表明整个字符串必须匹配该模式。
^spam 意味着字符串必须以spam 开始。
spam$意味着字符串必须以spam 结束。
4 s 和S
s 空格、制表符或换行符(可以认为是匹配“空白”字符);
S 除空格、制表符和换行符以外的任何字符;
5 问号?、星号*、加号+、半角句号.
? 匹配零次或一次前面的分组。
* 匹配零次或多次前面的分组。
+ 匹配一次或多次前面的分组。
. 匹配所有字符,换行符n除外。
问号?在正则表达式中可能有两种含义:声明非贪心匹配或表示可选的分组。这两种含义是完全无关的。
在字符串’HaHaHaHaHa’中,因为(Ha){3,5}可以匹配3 个、4 个或5 个实例,你可能会想,为什么在前面花括号的例子中,Match 对象的group()调用会返回’HaHaHaHaHa’,而不是更短的可能结果。毕竟,’HaHaHa’和’HaHaHaHa’也能够有效地匹配正则表达式(Ha){3,5}。
Python 的正则表达式默认是“贪心”的,这表示在有二义的情况下,它们会尽可能匹配最长的字符串。花括号的“非贪心”版本匹配尽可能最短的字符串,即在结束的花括号后跟着一个问号。
{n,m}?或*?或+?对前面的分组进行非贪心匹配。
大括号{}
表示匹配{}前面分组的次数。
{n}匹配n 次前面的分组。
{n,}匹配n 次或更多前面的分组。
{,m}匹配零次到m 次前面的分组。
{n,m}匹配至少n 次、至多m 次前面的分组。
{n,m}?或*?或+?对前面的分组进行非贪心匹配。
6 u4e00-u9fa5
表示汉字unicode编码方式下的编码范围,多达20892方块字(5*16*16*16=20480)。
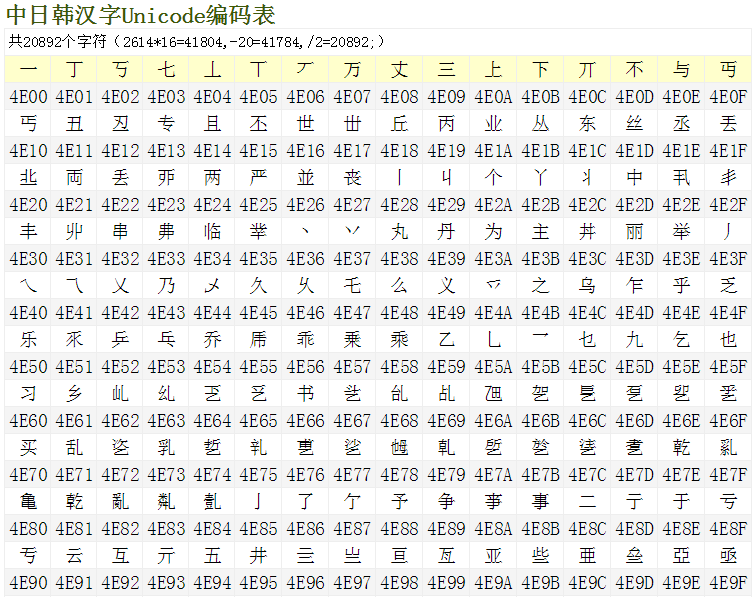

后面部分:

最后一个方块字是龥,yù,呼也。UniCode CJK编码:U+9FA5,五笔:WGKM
7 小括号()
有时候,你可能需要使用匹配的文本本身,作为替换的一部分。替换时使用1、2、3……。表示“在替换中输入分组1、2、3……的文本”。(可以理解为需要保留部分)
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。match方法配合用()表示的就是要提取的分组(Group)。
比如^(d{3})-(d{3,8})$分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
>>> m = re.match(r’^(d{3})-(d{3,8})$’, ‘010-12345’)
>>> m.group(0)
‘010-12345’
>>> m.group(1)
‘010’
>>> m.group(2)
‘12345’
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
8 Regex对象的sub()方法
正则表达式不仅能找到文本模式,而且能够用新的文本替换掉这些模式。Regex对象的sub()方法需要传入两个参数。第一个参数是一个字符串,用于取代发现的匹配。第二个参数是一个字符串,即正则表达式。
sub()方法返回替换完成后的字符串。如:
resup =re.compile(r'([d*])’) # 上标处理
s = resup.sub(r'<sup>1</sup>’, s)
9 re的findall()方法
findall()方法将返回一组字符串,包含被查找字符串中的所有匹配。(search()将返回一个Match对象,包含被查找字符串中的“第一次”匹配的文本。)
利用findall()方法,可以找到“所有”匹配的地方。另一方面,findall()不是返回一个Match 对象,而是返回一个字符串列表。以下两种写法都可以:
list1 = re.findall(pattern,strs)
list1 = pattern.findall(strs)
10 split()方法
split()方法提供强大了字符串切割功能,可以按正则表达式指定的字符进行切割,返回一个列表。
如用空格切割:
>>> ‘a b c’.split(‘ ‘)
[‘a’, ‘b’, ”, ”, ‘c’]
用多个空格切割:
>>> re.split(r’s+’, ‘a b c’)
[‘a’, ‘b’, ‘c’]
用多个字符进行切割:
re.split(r'[s,;]+’, ‘a,b;; c d’)
[‘a’, ‘b’, ‘c’, ‘d’]
关于中文字符匹配,为了加深理解,可以再看一下下面的例子:
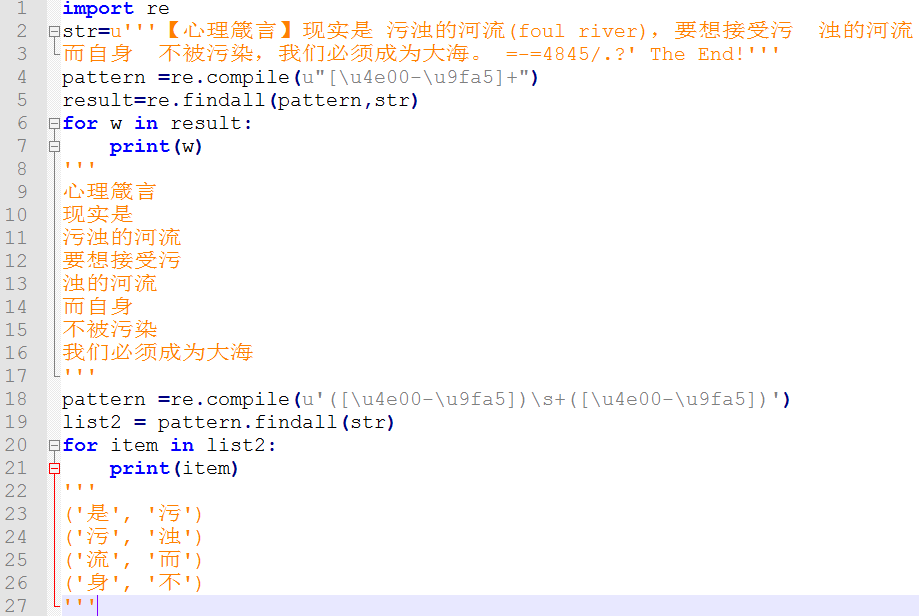

常用正则表达式,可以总结一下:
?匹配零次或一次前面的分组。
*匹配零次或多次前面的分组。
+匹配一次或多次前面的分组。
{n}匹配n 次前面的分组。
{n,}匹配n 次或更多前面的分组。
{,m}匹配零次到m 次前面的分组。
{n,m}匹配至少n 次、至多m 次前面的分组。
{n,m}?或*?或+?对前面的分组进行非贪心匹配。
^spam 意味着字符串必须以spam 开始。
spam$意味着字符串必须以spam 结束。
.匹配所有字符,换行符除外。
d、w 和s 分别匹配数字、单词和空格。
D、W 和S 分别匹配出数字、单词和空格外的所有字符。
[abc]匹配方括号内的任意字符(诸如a、b 或c)。
[^abc]匹配不在方括号内的任意字符。
字符|称为“管道”。希望匹配许多表达式中的一个时,就可以使用它。例如,正则表达式r’Batman|Tina Fey’将匹配’Batman’或’Tina Fey’。
正则表达式以外的其它补充:
字符串的strip()方法:可以删除掉字符串首尾两端的空格,包括n,还可以删除掉首尾两端的指定字符,形式如strip([str])。strip()方面的功能可以分解为lstrip()和rstrip()。
附代码:
import re
f0 = open(‘new.txt’,’w’,encoding=”UTF-8″)
#处理文本中的空格,只要含有“英文+空格+英文”就不处理
pattern =re.compile(u”[a-zA-Z]+s+[a-zA-Z]+”)
with open(‘text.txt’, ‘rU’) as file:
….strs = file.read()
….entxt = re.findall(pattern,strs)
if (not entxt):
”’
….s = s.replace(‘.’ , ‘。’)
….s = s.replace(‘,’ , ‘,’)
….s = s.replace(‘!’ , ‘!’)
….s = s.replace(‘?’ , ‘?’)
….”’
….s = strs.replace(‘ ’,”) # 处理全角空格
….s = s.replace(‘ ‘ , ”) # 处理半角空格(全中文可以使用)
….f0.write(s)
….f0.close()
else:
….pattern =re.compile(r'([u4e00-u9fa5,]{1})s+([u4e00-u9fa5,]{1})’)
….with open(‘text.txt’, ‘rU’) as f2:
……..str = f2.readline()
……..while str: # readline()方法读到最后会返回一个空字符
…………s = str.replace(‘ ’,”) # 处理全角空格
…………s = pattern.sub(r’12’, str)
…………s = s.strip() + “n” # strip()方法会把尾端的n也去掉
…………f0.write(s)
…………str = f2.readline() # readline()方法每次只读取一行
….f0.close() # 如果不是使用上面的with方法,需要close()后文档才会写入nex.tx
-End-
相关推荐
2020年java好找工作吗(java程序员的工资待遇)
Java程序员找工作很难吗?可能没有get这些内容 五分钟阅读下方文章 经常面试一些候选人,整理了下我面试使用的题目,陆陆续续整理出来的题目很多,所以每次会抽一部分来问。答案会在后…
java学起来难吗,培训java编程费用标准
在越来越多编程语言出现的时期,Java编程语言从未曾被淘汰过,在如今的大数据时代,Java编程语言仍占据着重要的位置,但是也有不少喜欢Java开发想要学习Java编程的小伙伴有一些…
java好找工作吗,java就业前景和工资待遇
无论是从每个月的编程语言排行榜上看,还是从各大招聘网站人才招聘需求上看,Java依然是IT行业中最热门、最抢手的编程语言。但很多想要学习Java进入编程行业的人还是会担忧武汉Jav…
如何优化代码运行速度,Java性能调优技巧
可供程序利用的资源(内存、CPU时间、网络带宽等)是有限的,优化的目的就是让程序用尽可能少的资源完成预定的任务。优化通常包含两方面的内容:减小代码的体积,提高代码的运行效率。本文讨…
java架构师简历模板,月薪过万的Java开发简历写法
看到这样的描述 你如果作为面试官 你是什么感觉 有朋友问,那正确的姿势是什么呢? 答案是多站在面试官的角度思考,这就是最正确的方向! 三年java程序员: 五年java程序员: 架…
内部oa系统开发是什么,java开源oa系统源码
OA就是办公自动化,它是企业为了更好的管理而使用的一种手段,它是一种软件系统,可以与网络连接,从而实现与企业的客户,员工之间等的交流。OA办公系统强调的就是办公的便捷方便,提高效率…

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。