前言
作为喜欢读书的我,也是很喜欢打游戏的,之前看到有人爬王者荣耀的皮肤的,我可是王者荣耀的老玩家了,所以我把英雄联盟给爬了。
哈哈哈,没想到吧!
在本次的爬虫教程的过程中,我也会分享给大家一些简单实用的爬虫小技巧。
夜太美,爬虫就没那么危险
在爬取的时候,不要猛攻嘛~,啊啊。。人家服务器受不了啊。。。
你要学会停顿,克制一点,该 sleep 就 sleep。
趁着人家睡觉的时候,限制防范程度是最低的,能晚点就晚点爬,没有看过凌晨4点的洛杉矶,但是你还可以看到凌晨4点的爬虫呢。
这样你的IP地址才不会容易被封。

这里多说一句,小编是一名python开发工程师,这里有我自己整理了一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些资料的可以关注小编,并私信“01”领取。
善于利用他人的UA
如果你在看别人网站的robots.txt,你就会看到别人的声明,声明什么内容可以爬,什么内容不可以爬。但是,不要忽略了人家的声明,希望给什么搜索引擎爬,比如下面这个
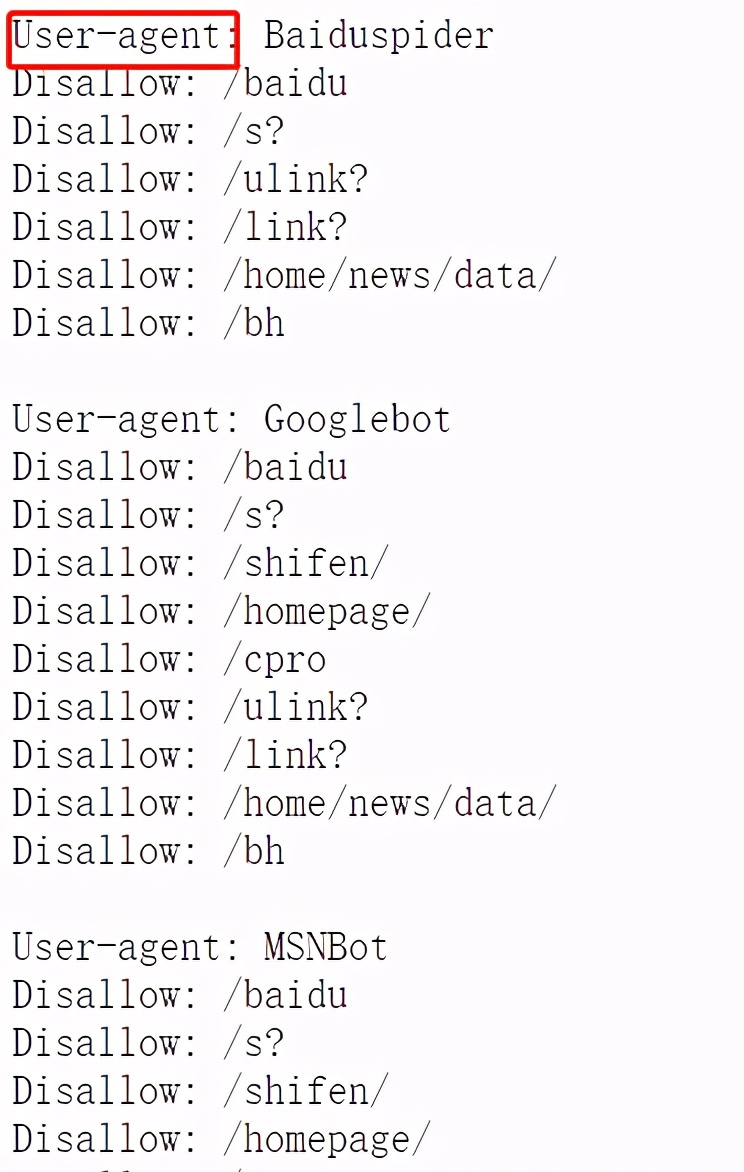
看到没,这个别人定义的robots.txt值得注意的是User-Agent,那么当你在Python构造headers的时候,User-Agent就直接指定它们的robots定义的就好了啊,比如:百度的UA,Google的UA或者是搜狗的UA等等。你再去爬爬看,那叫一个友好啊。
爬虫过程
分析网页
通过开发者模式F12,你就会发现箭头所指的文件了,没有看到的话,刷新一下试试。
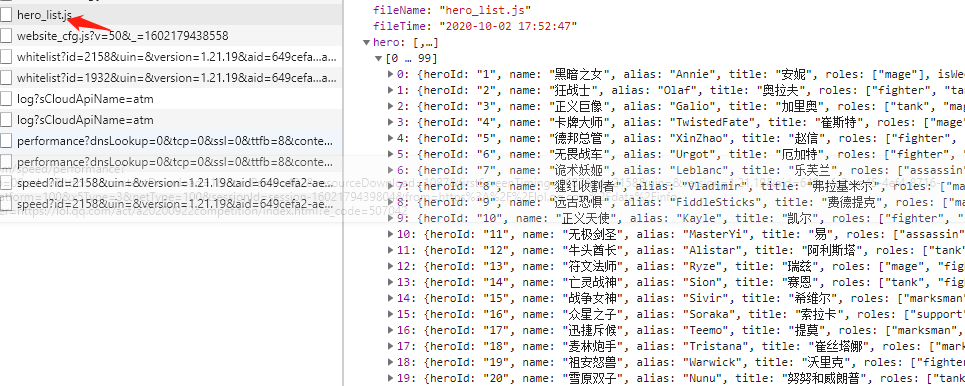
url0 = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
try:
response = requests.get(url0, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding # 设置编码格式
hreolist = response.json() # 将Response转换成json格式
print(hreolist) # 打印出英雄列表
print(len(hreolist['hero'])) # 打印英雄个数:151
except Exception as e:
print(e)
复制代码
通过上面的代码,我成功的获取到了所有的英雄,以及英雄的总个数。
这里只是截取部分的打印信息
{'hero': [{'heroId': '1', 'name': '黑暗之女', 'alias': 'Annie', 'title': '安妮', 'roles': ['mage'], 'isWeekFree': '0', 'attack': '2', 'defense': '3', 'magic': '10', 'difficulty': '6', 'selectAudio': 'https://game.gtimg.cn/images/lol/act/img/vo/choose/1.ogg', 'banAudio': 'https://game.gtimg.cn/images/lol/act/img/vo/ban/1.ogg', 'isARAMweekfree': '0', 'ispermanentweekfree': '0', 'changeLabel': '无改动', 'goldPrice': '4800', 'couponPrice': '2000', 'camp': '', 'campId': '', 'keywords': '安妮,黑暗之女,火女,Annie,anni,heianzhinv,huonv,an,hazn,hn'}
复制代码
通过上面的json信息其实你会发现,英雄的列表信息是写在了hero下的。
获取每一位英雄的ID值
通过刚刚获取到的json值,你会发现,这些值里面有一个键:'heroId',那么这个'heroId'是用来做什么的呢?
这个我开始是不知道的,接下来我进入到了皮肤原画的网址,马上就霍然开朗了
安妮
奥拉夫
莉莉娅
复制代码
通过上面的三个URL地址你就会发现heroId就是一个查询参数id。
但是在这里有一个坑,想必你也看到了,英雄的个数只有151个,id值却是876,。没错,在前100多个英雄都不会有什么问题很有规律,但是100多之后就出现问题了,每个英雄的id值跳转的很多,所以要进入每一位英雄的原画去爬图片就必须要正确拼接URL。每位英雄的ID值获取就成了必不可少的一步。
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
hero_list_json = hreolist
hero_lists = hero_list_json['hero'] # 获取英雄列表
heros_id = list(map(lambda x: x['heroId'], hero_lists)) # 获取英雄编号
复制代码
分析原画网页
打开开发者模式,你会发现一个文件
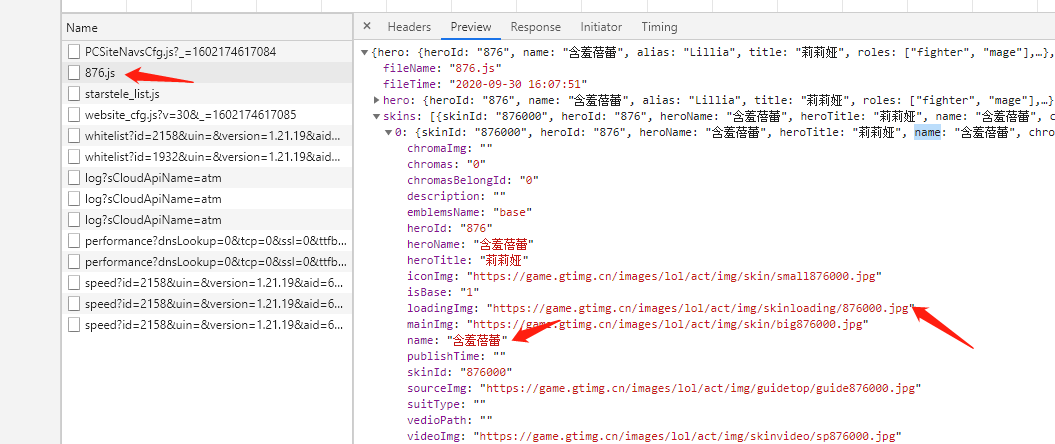
在上图中可以看到skins有10个值,点开第一个可以看到loadingImg,而这个键对应的值就是皮肤原画的URL地址。
当然,作为老玩家们都知道,莉莉娅只有两种皮肤,但是skins里面为什么有10个值,依次点开第三个至第十个,会发现其余的loadingImg的值都是空的。
url_list = [] # 保存每一位英雄信息的url地址
for hero_id in heros_id:
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(hero_id)
# print(url)
url_list.append(url)
复制代码
url1 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/876.js'
try:
response = requests.get(url1, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding # 设置编码格式
hreo_info = response.json()
skins = hreo_info['skins'] # 获取英雄皮肤信息
# 遍历每一个皮肤的loadingImg与皮肤名称
for skin in skins:
print(skin['loadingImg'])
print(skin['name'])
except Exception as e:
print(e)
复制代码
通过上面的两组代码的思路,那么已经可以实现一个英雄的皮肤原画的爬取了,需要获取所有的皮肤原画,无非就是多一个循环。
当你会爬第一个英雄的原画时,你还怕得不到其他英雄吗?
结语
爬取英雄联盟的英雄原画的思路已经分享给大家了。
请问亲爱的读者,你是否可以将王者荣耀的英雄皮肤全部拿下呢?
相信你绝对是没有问题的,加油!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 394062665@qq.com 举报,一经查实,本站将立刻删除。

英雄联盟录制画质怎么提

LOL上单狮子狗出装(bb

英雄联盟空格键怎么设置

LOL红惩戒和蓝惩戒区别(

英雄联盟无限火力出装(

LOL猩红收割者出装顺序(

lol界面红框怎么取消(

